









- Pick the Right Approach
The first and foremost thing is to choose appropriate tools and frameworks to build a data pipeline as it has a huge impact on the overall development process. There are two extreme routes and many variants one can choose between.- The first option is to select a data integration platform that offers graphical development environments and fully integrated workflows for building ETL pipelines. It seems to be very promising but often turns out to be the tough one as it lacks some significant features.
- Another option would be to create a data pipeline using powerful frameworks like Apache Spark, Hadoop. While this approach implies a much higher effort upfront, it often turns out to be more beneficial since the complexity of the solution can grow with your requirements.
- Lazy evaluation in Apache Spark can overcome time complexity. The time gets saved as operations won’t get executed until it is triggered.
- Spark has a DAG execution engine that facilitates in-memory computation and acyclic data flow resulting in high speed. Here, the data is being cached so that it does not fetch data from the disk every time thus the time is saved.
- Scala – It is generally good to use Scala when doing data engineering (read, transform, store). For implementing new functionality not found in Spark, Scala is the best option as Apache Spark is written in Scala. Although Spark well supports UDFs in Python, there will be a performance penalty, and diving deeper is not possible. Implementing new connectors or file formats with Python will be very difficult, maybe even unachievable.
- Python – In the case of Data Science, Python is a much better option with all those Python packages like Pandas, SciPy, SciKit Learn, Tensorflow, etc.
- R – It is popular for research, plotting, and data analysis. Together with RStudio, it makes statistics, plotting, and data analytics applications. It is majorly used for building data models to be used for data analysis.
- Java – It is the least preferred language because of its verbosity. Also, it does not support Read-Evaluate-Print-Loop (REPL) which is a major deal-breaker when choosing a programming language for big data processing.
- Working With Data
However, as data starts increasing in volume and variety, the relational approach does not scale well enough for building Big Data applications and analytical systems. Following are some major challenges –- Managing different types and sources of data, which can be structured, semi-structured, or unstructured.
- Building ETL pipelines to and from various data sources, which may lead to developing a lot of specific custom code, thereby increasing technical debt over time.
- Having the capability to perform both traditional business intelligence (BI)-based analytics and advanced analytics (machine learning, statistical modeling, etc.), the latter of which is challenging to perform in relational systems.
The ability to read and write from different kinds of data sources is unarguably one of Spark’s greatest strengths. As a general computing engine, Spark can process data from various data management and storage systems, including HDFS, Hive, Cassandra, and Kafka. Apache Spark also supports a variety of data formats like CSV, JSON, Parquet, Text, JDBC, etc.
- Writing Boilerplate Code
Boilerplate code refers to sections of code that have to be included in many places with little or no alteration.- RDDs – When working with big data, programming models like MapReduce are required for processing large data sets with a parallel, distributed algorithm on a cluster. But MapReduce code requires a significant amount of boilerplate.This problem can be solved through Apache Spark’s Resilient Distributed Datasets, the main abstraction for computations in Spark. Due to its simplified programming interface, it unifies computational styles which were spread out in otherwise traditional Hadoop stack. RDD abstracts us away from traditional map-reduce style programs, giving us interface of a collection(which is distributed), and hence a lot of operations that required quite a boilerplate in MapReduce are now just collection operations, e.g. groupBy, joins, count, distinct, max, min, etc.
- CleanFrames – Nowadays, data is everywhere and drives companies and their operations. The data’s correctness and prominence reserves a special discipline, known as data cleansing, which is focused on removing or correcting course records. M/e involves a lot of boilerplate code. Therefore, Spark offers a small library CleanFrames to make data cleansing automated and enjoyable. Simply import the required code and call the clean method. The clean method expands code through implicit resolutions based on a case class’s elements. The Scala compiler applies a specific method to a corresponding element’s type. CleanFrames come with predefined implementations that are available via a simple library import.
- Writing Simple And Clear Business Logic
Business logic is the most important part of an application and it is the place where most changes occur and the actual business value is generated. This code should be simple, clear, concise, and easy to adapt to changes and new feature requests.Some features offered by Apache Spark for writing business logic are –- RDD abstraction with many common transformations like filtering, joining, and grouped aggregations are provided by the core libraries of Spark.
- New transformations can be easily implemented with so-called user-defined functions (UDFs), where one only needs to provide a small snippet of code working on an individual record or column and Spark wraps it up such that it can be executed in parallel and distributed in a cluster of computers.
- Using the internal developers API, it is even possible to go down a few layers and implement new functionalities. This might be a bit complex, but can be very beneficial for those rare cases which cannot be implemented using user-defined functions (UDFs).
To sum up, Spark is preferred because of its speed and the fact that it’s faster than most large-scale data processing frameworks. It supports multiple languages like Java, Scala, R, and Python and a plethora of libraries, functions, and collection operations that helps write clean, minimal, and maintainable code.
Big Data Analytics with Hadoop and MapReduce was powerful, but often slow, and gave users a low-level procedural programming interface that required people to write a lot of code for even very simple data transformations. However, Spark has been found to be optimal over Hadoop, for several reasons:
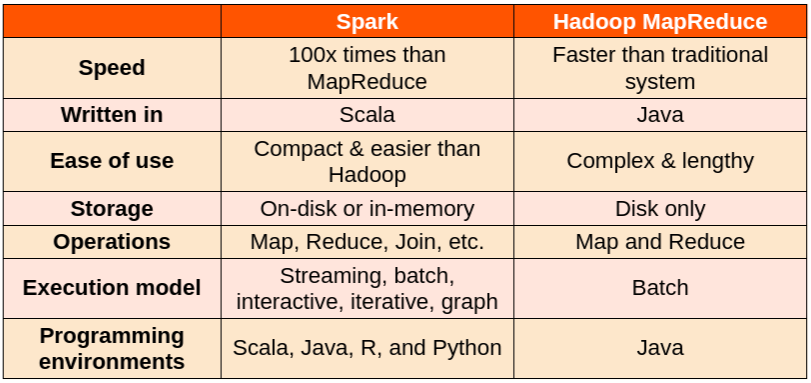
Spark was designed to be a Big Data tool from the very beginning. It provides out-of-the-box bindings for Scala, Java, Python, and R.

