









Amazon Elasticsearch Service is a fully managed service that enables you to search, analyze, and visualize your log data cost-effectively, at petabyte-scale. It manages the setup, deployment, configuration, patching, and monitoring of your Elasticsearch clusters for you, so you can spend less time managing your clusters and more time building your applications. With a few clicks in the AWS console, you can create highly scalable, secure, and available Elasticsearch clusters.
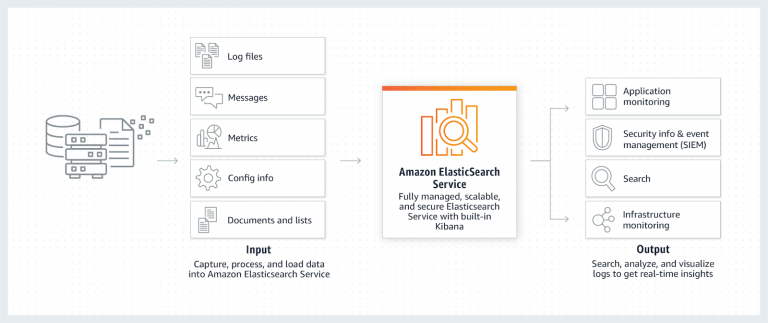
How is AWS Elasticsearch Costs Calculated?
Elasticsearch consists of Master and Data nodes. AWS ES does not cost anything for the usage of service. The only cost you bear is the instance code. Here are 2 types of nodes in ES.
Master nodes
Master nodes play a key role in cluster stability, and that’s why we recommend using a minimum of 3 dedicated master nodes for production clusters, spread across 3 AZs for HA. It doesn’t have additional storage requirements, so only compute costs are incurred.
Data nodes
Deploying your data nodes into three Availability Zones can also improve the availability of your domain. When you create a new domain, consider the following factors:
- Number of Availability Zones
- Number of replicas
- Number of nodes
Note that all types of EC2 instances are not available for ES, only a subset is allowed to run as either data or master node.
Don’t use T2 instances as data nodes or dedicated master nodes. As these are burstable, you don’t get dedicated CPUs. Also, they don’t allow UltraWarm setup for cost-effectiveness.
Storage
Another factor to consider while tracking cost is EBS Storage attached to data nodes. Even though storage costs are smaller compared to nodes, on a petaByte scale, it becomes significant. Use provisioned IOPS only when it is required; these cost 1.5x of general-purpose SSD.
UltraWarm
This is an option with AWS ES to optimize storage and, thus, cost. With UltraWarm Enabled, you will have another node which moves your infrequently accessed data to S3, instead of EBS. Choosing S3 saves costs for archived or infrequent accessed data. The only cost you pay with UltraWarm is the cost of the chosen storage. UltraWarm has 2 node types – Medium(1.6 TB capacity) and Large(20 TB capacity). And the minimum number of node types is 2, i.e. 2 medium or 2 large. Choose this option only when you are dealing with large scale storage.
Elasticsearch Monitoring & Analysis
The first step to optimize cost is to become cost and usage aware; monitor existing domain with these tools.
AWS Cost Explorer
Use billing and cost explorer services to get a breakdown of the total cost.

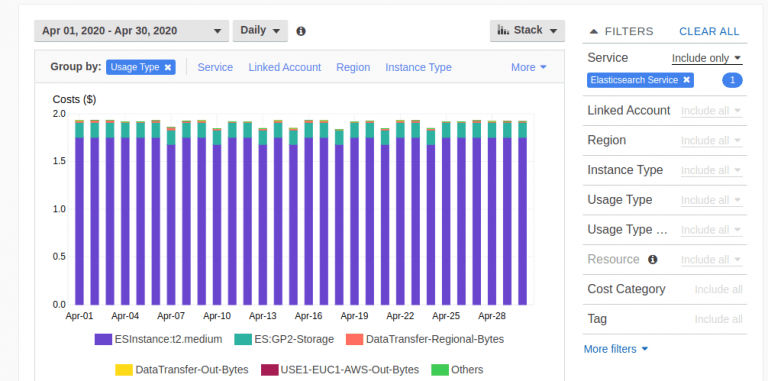
Event Monitoring
Amazon Elasticsearch Service provides built-in event monitoring and alerting, enabling you to monitor the data stored in your cluster and automatically send notifications based on pre-configured thresholds. Built using the Open Distro for Elasticsearch alerting plugin, this feature allows you to configure and manage alerts using your Kibana interface and the REST API, and receive notifications.
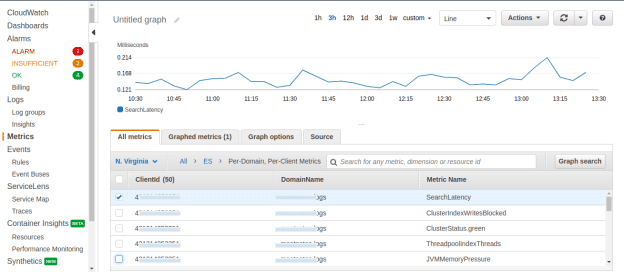
Here are some screenshots of those metrics. These allow you to understand the actual resource requirements of your ES domain.
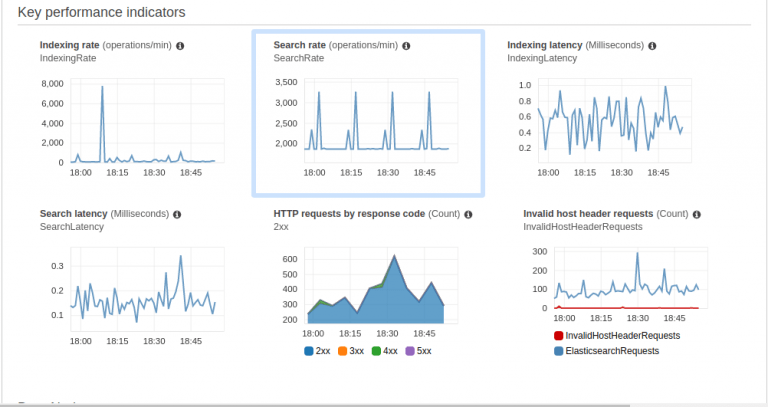
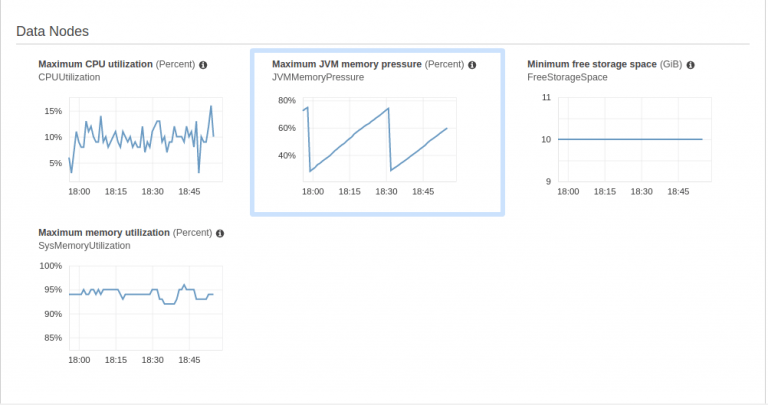
CloudWatch
You can also get CloudWatch-based metrics. These are charged per-metrics and per-domain basis, which helps in getting the insight into the utilization per node. Check out recommended metrics on the AWS website.
Controlling Elasticsearch costs
To control costs, you need to answer the following first based on the above metrics –
- How many and what type of data nodes you need?
- How many shards do you need?
- How many replicas do you need?
- How frequently do you access the data?
Pre-process your data -Most often we find redundant and duplicate events in our log files since we aggregate data from multiple sources. Hence, ensure that the data you store in ES is relevant, and also try to reduce or dedup your logs. Another type of preprocessing can be done by sending a reduced stream to Elasticsearch, and for this, you can use Kinesis Firehose.
Archive Data – Blocks of data that are accessed less frequently should be moved to S3 using UltraWarm if at all required. Use policies to run tasks like archival, re-indexing, deleting old indexes regularly, etc. to make it an automated process.
Overheads – Underlying OS and ES has its own storage overheads to run and manage nodes. So, you will have to provision a lot more than the actual source data. 5% of OS requirements per node, 20% of ES requirements per node, and 10% storage for indexes per node is minimum overhead; multiply all that by 2 to fulfill replica and HA requirements. Thus, the actual storage available is less than you pay for. An AWS recommended formula for same is –Source Data * (1 + Number of Replicas) * 1.45 = Minimum Storage Requirement
The number of shards – Each shard should have at least one replica. So, by choosing the wrong number of shards, you’re adding more than 2x the storage problem. A recommended way to calculate shards is provided by AWS, but a more pragmatic approach we took, was to break down your storage requirements into chunks of ~25 GBs. This size is big enough to properly use the available RAM size in nodes but not big enough to cause CPU errors by most node types, in AWS ES instance types. To be more specific, ensure that a single shard can be loaded in memory and processed easily. But, keep Memory Pressure in mind, i.e. only 75% of memory should be used by queries. Read more in the JVM section below.
Number of Nodes – If you read all the above points carefully and combine them, it makes sense for you to have a minimal number of nodes, i.e. 3 AZs should have 3 nodes. Fewer nodes will result in lesser overhead related wastage.
Use VPC – Using VPC and 3 different subnets for 3 AZs is not only secure, but you can also reduce the data transfer cost over the internet.
Use reserved instances – You can reserve instances for a one or three year term, to get significant cost savings on usage as compared to on-demand instances.
Snapshots – You can build data durability for your Amazon Elasticsearch cluster through automated and manual snapshots. A manual backup will cost you S3 storage prices. By default, the Amazon Elasticsearch Service will automatically create hourly snapshots of each domain and retain them for 14 days at no extra charge. However, choosing manual or relying on automated snapshots should be a business decision based on affordable downtime, RTO, and RPO requirements.
JVM Factor – Elasticsearch is a java based application. Hence, it requires java virtual memory for the better running of an elasticsearch. Few tips –
- Use memory-optimized instance types.
- Avoid queries on wide ranges, such as wildcard queries.
- Avoid sending a large number of requests at the same time.
- Avoid aggregating on text fields. This helps prevent increases in field data. The more field data that you have, the more heap space is consumed. Use the GET _cluster/stats API operation to check field data. For more information about field data, see the Elastic website.
- If you must aggregate on text fields, change the mapping type to a keyword. If JVM memory pressure gets too high, use the following API operations to clear the field data cache: POST /index_name/_cache/clear (index-level cache) and POST */_cache/clear (cluster-level cache).
Conclusion
Cost optimization is not a one time task, and you should keep a constant eye on the requirements and cost explorer to understand the exact need. Observe the monitoring charts, since, if the data reduces, then Elasticsearch usage will also reduce that can help in minimizing the number of nodes, shards, storage, and replicas.

