









sudo pip3 install SpeechRecognition
This is the simplest way to install the SpeechRecognition Module.
Audio files that support speech recognition are wav, AIFF, AIFF-C, and FLAC. I have used the ‘wav’ file in this example.
Step 2: speechRecognition.Recognizer() # Initializing recognizer class in order to recognize the speech. We are using google speech recognition.
Step 3: recogniser.recognize_google(audio_text) # Converting audio transcripts into text.
Step 4: Converting specific language audio to text.
Audio file to text conversion
def startConvertion(path = 'sample.wav',lang = 'en-IN'):
with sr.AudioFile(path) as source:
print('Fetching File')
audio_text = r.listen(source)
# recoginize_() method will throw a request error if the API is unreachable, hence using exception handling
try:
# using google speech recognition
print('Converting audio transcripts into text ...')
text = r.recognize_google(audio_text)
print(text)
except:
print('Sorry.. run again...')
recognize_google(audio_text, language = lang)
Please refer this link for language code:
https://cloud.google.com/speech-to-text/docs/languages
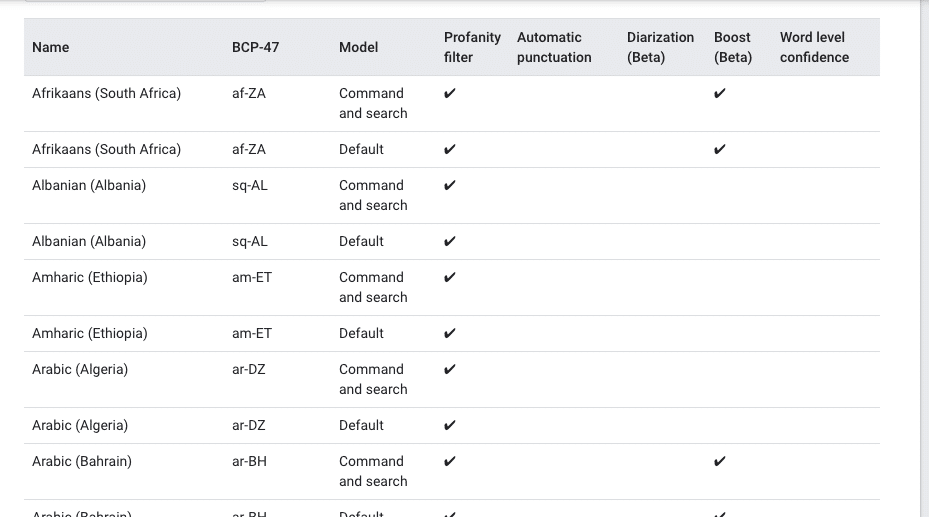
Example:
recognize_google(audio_text, language = "hi-IN")
Full Code:
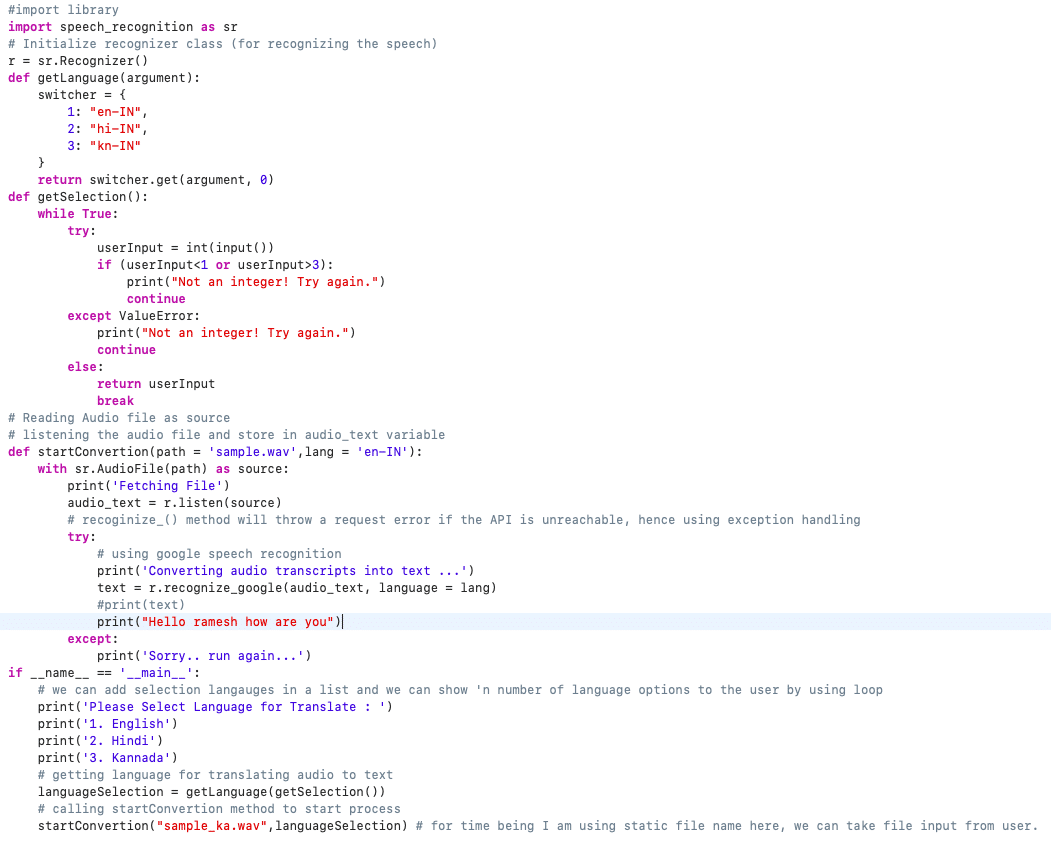
Output
English audio

Hindi audio

Kannada audio

This blog demonstrates how to convert different language audio files using the Google speech recognition API. Google speech recognition API is an easy method to convert speech into text, but for it to operate, it requires an internet connection.
If you have anything to add, please feel free to leave a comment.
Thanks for reading.

