









Originally, Kafka was designed as a message queue, but we know today that Kafka has several functions and elements as a distributed streaming platform. We can use Apache Kafka as:
- Messaging System: a highly scalable, fault-tolerant and distributed Publish/Subscribe messaging system.
- Storage System: a fault-tolerant, durable and replicated storage system.
- Streaming Platform: on-the-fly and real-time processing of data as it arrives.
Kafka can either be run in a standalone mode or distributed mode. A Kafka cluster typically consists of a number of brokers that run Kafka. Within the broker there is a process that helps publish data (push messages) into Kafka topics, this process is titled as Producers. A consumer of topics pulls messages off a Kafka topic. In order to achieve high availability, Kafka has to be set up in the form of a multi-broker or multi-node cluster. As a distributed cluster, Kafka brokers ensure high availability to process new events. Kafka, being fault-tolerant, the replicas of the messages are maintained on each broker and are made available in case of failures. With the help of the replication factor, we can define the number of copies of the topic across the cluster.
Adding new brokers to an existing Kafka cluster is as simple as assigning a unique broker id, listeners and log directory in the server.properties file. However, these brokers will not be assigned any data partition of the existing topics in the cluster, unless the partitions are moved or new topics are created the brokers won’t be doing much work. Certain clusters are called as unbalanced clusters because of the following problems:
One of the easiest ways to detect them is with the help of a Kafka Manager. This interface makes it easier to identify topics and partition leaders that are unevenly distributed across the cluster. It supports the management of multiple clusters, preferred replica election, replica re-assignment, and topic creation. It is also great for getting a quick bird’s eye view of the cluster.
An unbalanced cluster can generate unnecessary disk, CPU problems or even the need to add another broker to handle unexpected traffic. The following constraints have to be kept in mind while rebalancing your cluster:
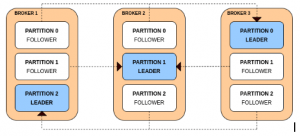
All the reads and writes on a partition goes to the leader. Followers send fetch requests to the leaders to get the latest messages from them. Followers only exist for redundancy and fail-over.
Consider a scenario where a broker has failed. The failed broker might have been a host of multiple leader partitions. For each leader partition on a failed broker, its followers on the rest of the brokers are promoted as the leader. For the follower to be promoted as the leader it has to be in sync with the leader as fail-over to an out-of-sync replica is not allowed.
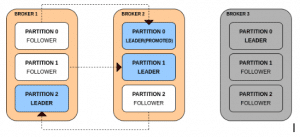
If another broker goes down then all the leaders are present on the same broker with zero redundancy.
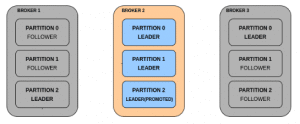
When both the brokers 1 and 3 come online, it gives some redundancy to the partitions but the leaders remain concentrated on broker 2.
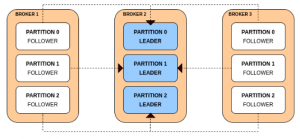
This leads to a leader unbalance across the Kafka brokers. The cluster is in a leader skewed state when a node is a leader for more partitions than the number of partitions/number of brokers. In order to solve this, Kafka has the facility of reassigning leaders to the preferred replicas. This can be done in two ways:
- The broker configuration auto.leader.rebalance.enable=true allows the controller node to reassign leadership back to the preferred replica leaders and thereby restore the even distribution.
- Running Kafka-preferred-replica-election.sh forces the election of the preferred replica for all partitions: The tool takes a mandatory list of zookeeper hosts and an optional list of topic partitions provided as a JSON file. If the list is not provided, the tool queries zookeeper and gets all the topic partitions for the cluster. It might be a tedious task to run the Kafka-preferred-replica-election.sh tool. Customized scripts can render only the necessary topics and their partitions and automate the process across the cluster.

The topic “unbalanced_topic” is skewed on the brokers 3,4 and 5. Why?
A broker is said to be skewed if its number of partitions is greater than the average of partitions per broker on the given topic.
It can be solved by using the following steps:
- Using partition reassignment tool (Kafka-reassign-partition.sh), generate (with the –generate option) the candidate assignment configuration. This shows the current and proposed replica assignments.
- Copy the proposed assignment to a JSON file.
- Execute the partition reassignment tool to update the metadata for balancing.
- Once the partition reassignment is completed, run the “Kafka-preferred-replica-election.sh” tool to complete the balancing.
The Kafka-reassign-partitions.sh has its limitations as it is not aware of partitions size, and neither can provide a plan to reduce the number of partitions to migrate from brokers to brokers. By trusting it blindly, you will cripple your Kafka cluster performance.
A customized script can be written which would render the optimal assignment of the partitions. The script should follow the steps below:
- Obtain input from the user for the topic which has to be rebalanced.
- Capture the existing configuration of the Kafka Cluster and identify the brokers on which the particular topic is skewed. This information should consist of the number of partitions (NOP), partitions and Leader partitions for each broker.
- After obtaining the above information, we can calculate the optimal number of partitions per broker. (Optimal number of partitions (ONOP) = Total number of partitions across all brokers/ Total number of brokers)
- Form a path for reassignment of partitions in such a way that the partitions are moved from the Brokers whose NOP > ONOP to the Brokers whose NOP < ONOP. Make sure that the Leader partitions have minimal movement. This step has to be iterative.
- Output the information into a JSON file which is acceptable to be run with “Kafka-preferred-replica-election.sh”. The format to be followed can be obtained using the partition reassignment tool “Kafka-reassign-partition.sh” by generating a candidate assignment configuration.
Note that the above script takes the Topic name as the user input and output the JSON file with respect to the particular Topic. Once the reassignment is successful for all partitions, we can run the preferred replica election tool to balance the topics and then run “describe topic” to check the balancing of topics. On the whole, rebalancing your Kafka is the process where a group of consumer instances (belonging to the same group) co-ordinate to own a mutually exclusive set of partitions of topics that the group is subscribed to. At the end of a successful rebalance operation for a consumer group, every partition for all subscribed topics will be owned by a single consumer instance within the group.

