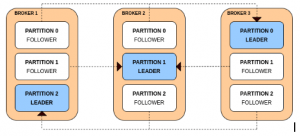
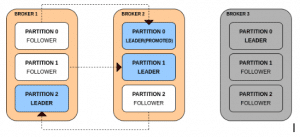
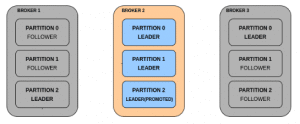
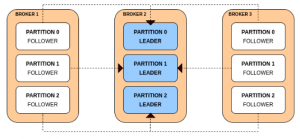
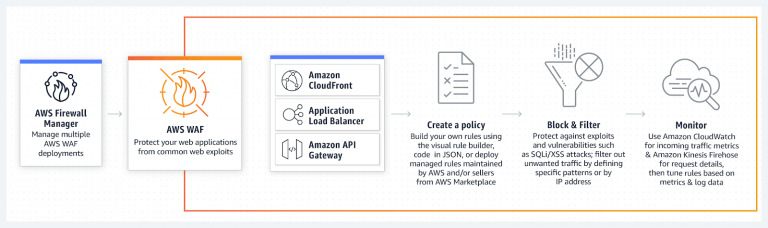
Why KIND?
- Supports multi-node (including HA) clusters
- Customizable base and node images
- Can use your local Kubernetes branch
- Written in go, can be used as a library
- Can be used on Windows, MacOS, and Linux
- CNCF certified conformant Kubernetes installer
Use-Cases:
- KIND in a ci pipeline
- Local development
- Demos of newer Kubernetes features
- Kinder tooling to test kubeadm
- “/test pull-Kubernetes-e2e-kind” on Kubernetes PRs for faster e2e feedback. It should be roughly 15-20 minutes currently.
- Go Version : go1.11.5 darwin/amd64
- Docker Version: docker-ce-18.09.2
Additional Requirements
Git Version: 2.17.2
Kubectl Version: 1.13.4 – 1.14.1
/usr/bin/ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)”
Installing wget:
brew install wget
Installing git :
brew install git
Installing kubectl:
To download version v1.14.0 on macOS, type:
curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.13.4/bin/darwin/amd64/kubectl
Make the kubectl binary executable :
chmod +x ./kubectl
Move the binary into your PATH :
sudo mv ./kubectl /usr/local/bin/kubectl
kubectl version
Making a cluster directory:
mkdir cluster
cd cluster
wget https://dl.google.com/go/go1.11.5.darwin-amd64.tar.gz
tar -xzf go1.11.5.darwin-amd64.tar.gz
The above action will create a folder named go with the binary files in it. Now we will export the go path and put the same in ~/.bash_profile to be working even after we log-off from the user.
export PATH=$PATH:$HOME/cluster/go/bin
Now run go version and it will give the go version extracted.
Put the same entry in bash_profile. If the file doesn’t exist then create one as,
vim ~/.bash_profile
export PATH=$PATH:$HOME/cluster/go/bin
For making the changes to take effect immediately, run :
source ~/.bash_profile
Checking the go environment variables are set as they should be:
go env
will give the following output. Make sure that the $GOPATH and $GOROOT have different directories.
Or
You can set up the GOPATH and GOROOT environment variables manually as:
export GOPATH=$HOME/go
export GOROOT=$HOME/cluster/go
Installing docker-ce:v18.09.2 from the following link:
https://hub.docker.com/editions/community/docker-ce-desktop-mac
Or
wget https://download.docker.com/mac/stable/Docker.dmg
and install the same.
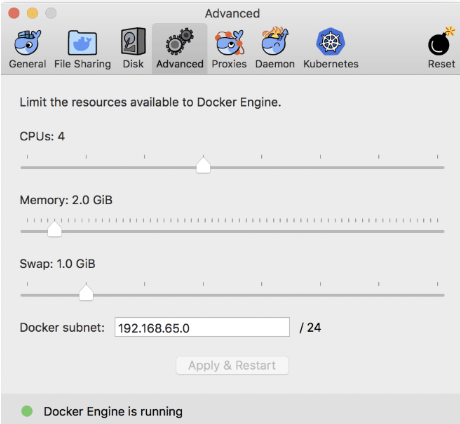
Memory to 2.0 GiB
Now we will get KIND for setting up k8s-cluster:
go get -u sigs.k8s.io/kind
It is almost 1.58 GB and will take a little time after that it will create a KIND folder in the GOPATH directory.
export PATH=$PATH:$HOME/go/bin
and add the same to ~/.bash_profile like previous additions.
kind version gives 0.3.0-alpha
Now for a KIND HA k8s-cluster we will need to create a configuration file:
Create a config.yml file in the directory cluster that we created initially. Get the following file from git repo:
wget https://github.com/shubhamsre/kind/blob/master/configha.yml
Run hostname to get the hostname of your system.
vim configha.yml
Change the hostname from my-hostname to your hostname

Now the power step is to run the setup for the cluster :
kind create cluster –name kindha –config configha.yml
The output is as follows:
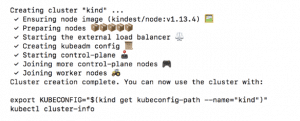
Export the Kube-configuration as:
export KUBECONFIG=”$(kind get kubeconfig-path –name=”kindha”)”
kubectl cluster-info
The below results will be given somewhat resembling this:
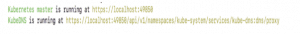
All the nodes must get to the ready state and they may take some time for the same :
Run kubectl get nodes -o wide to get node status for Kubernetes Cluster


Adding alias for kubectl can be done as :
alias k=’kubectl’
and adding the same to the ~/.bash_profile.
You can add a role to the worker node as :
kubectl get nodes
kubectl label node kind-worker node-role.kubernetes.io/node=
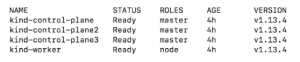
The ~/.bash_profile should have the following contents:
export PATH=$PATH:$HOME/go/bin
export PATH=$PATH$HOME/cluster/go/bin
export KUBECONFIG=”$(kind get kubeconfig-path –name=”kindha”)”
alias k=’kubectl’
alias K=’kubeadm’
“failed to init node with kubeadm: exit status 1”
It shows that it is an error message stating that kubeadm cannot perform a certain task so you need to increase the CPU cores and memory for the system.
While Creating the Cluster if you come across the following message
” Error: could not list clusters: failed to list nodes: exit status 1″
It means that this error message states that the docker is not running and before creating the cluster please ensure the docker is in running state.