Cloud Computing is the go-to solution for most businesses today. It makes work processes efficient, scalable and economical. It is net-centric, has a flexible architecture and is easily accessible.
However, cloud computing can still make businesses vulnerable. In a survey by Cloud Security Alliance, 73 percent said that data security was the primary concern inhibiting cloud adoption.
As companies begin to move data to the cloud, they have to implement policies and procedures that will enable their employees to take advantage of cloud computing without affecting the security of corporate data.
It is important to identify the top security issues and find remedial measures. In our earlier blog, we explored why businesses need Cloud-Native Architecture. In this blog, we explore the top security concerns for cloud computing.
Data Breach
Data Breaches result from an attack or employee negligence and error. This is a primary cause for concern in cloud platforms. Vulnerabilities in the application or ineffective security practices can also cause data breaches. Employees may log into cloud systems from their phones or personal laptops thus exposing the system to targeted attacks.
CSA defines data breach as involving any kind of information that was not intended for public release, including personal health information, financial information, personally identifiable information, trade secrets, and intellectual property.
A study by the Ponemon Institute says that the chances of a data breach occurring were three times higher for businesses using the cloud. Data Breach isn’t new, but cloud computing has a particular set of attributes that make it more vulnerable.
Account Hijacking
With the increase in adoption of cloud services, organizations have reported an increased occurrence of account hijacking. Such attacks involve using employee’s login information to access sensitive information. Attackers can also modify, insert false information and manipulate the data present in the cloud. They also use scripting bugs or reused passwords to steal credentials without being detected.
Account hijacking could have a detrimental effect at the enterprise level, undermining the firm’s integrity and reputation. This could also have legal implications in industries such as healthcare where patients’ personal medical records are compromised. A robust IAM (Identity Access Management) system can prevent unauthorized access and damage to the organization’s data assets.
Insecure APIs and Interfaces
Customers can tailor their cloud computing experience according to their needs by using Application Programming Interface or APIs.
These are used to extract, manage and interact with information on the cloud. However, the unique characteristics of API leave the door wide open for threats. Hence the security of APIs affects the security and availability of cloud services and platforms.
APIs facilitate communication between applications, herein lies the vulnerability. Firms need to focus on designing APIs with adequate authentication, other access control methods, and encryption technology.
The most recent example of an insecure API was at Salesforce, where an API bug in its Marketing Cloud service exposed customer data. This caused data to be written from one customer account to another.
Insider Threat
An Insider threat is the misuse of information through hostile intent, malware, and even accidents. Insider threats originate from employees or system administrators, who can access confidential information They can also access even more critical systems and eventually data.
When the relationship between the employer and system administrator turn sour, they may resort to leaking privileged information.
There can be several instances of insider threat such as a Salesperson who jumps ship or a rogue admin. In scenarios where the cloud service provider is responsible for security, the risk from insider threat is often greater.
Insider threats can be circumvented through business partnerships, controlled access and prioritizing initiatives.
Malware Injections and APT (Advanced Persistent Threats)
Malware injections are scripts or code that is inserted into the cloud services and begin to mimic valid instances. When embedded into the cloud, they begin to change the normal execution of the code.
Once the malware injection and cloud systems begin to operate in sync attackers can affect the integrity and security of the data. SQL injection attack and cross-site scripting attack are seen very often.
The advanced persistent threat is another form of attack where they infiltrate the IT infrastructure. APTs are able to avoid detection for extended periods of time. APTs sync with normal network traffic by moving laterally through data center networks.
Tips for improving Security on the Cloud
Here are a few simple steps that you can take to utilize the power of the cloud without succumbing to the risks.
Authentication protocols: Implement two factor or multi-factor authentication for access to all cloud applications.
User Access Management: Ensure proper levels of authorization. Each employee should only be able to access data that is required to perform his job.
Monitor user activity: Irregularities in user activity can be detected if there is real-time monitoring. This can help you detect a breach early and implement remedial measures.
Ensure your offboarding process is thorough: Use a systematized deprovisioning system to stop access to the firm’s systems, data and customer information.
Data backup and recovery: A thorough plan can enable data retrieval with as little fuss as possible.
Drive Momentum with Cloud Computing without the Security Risks
Cloud is revolutionizing the way businesses work. It has opened new possibilities in access, storage and flexibility. ‘
It has also left systems wide open for a plethora of security threats. Analyzing the security risks that exist is the first step in building a comprehensive cloud computing strategy that can fuel business growth.
Are you ready to jump into the cloud? Read our blog on launching an enterprise-ready product on the cloud in a day.
Miriam Subiksha
#Business | 6 Min Read
Share:
The influx of technologies like Artificial Intelligence, Big Data, IoT and ML has rendered traditional businesses redundant. Rapidly changing customer needs force firms to evolve and adapt. Digital transformation is the new paradigm, that helps them stay ahead of the competition. Firms leverage the support of the cloud to set up robust digital transformation frameworks.
Cloud fuels innovation by giving a compatible set of APIs for developers. Firms can reuse enterprise data. Cloud offers analytics, functional programming, and low code platforms. It is essential for informed decision making. This ensures the faster launch of enterprise-ready products.
The rise of Cloud Computing and Digital Transformation
According to a survey by Logic Monitor, public cloud engagement and adoption is being driven by enterprises pursuing digital transformation. By 2020, a whopping 83% of workloads will be hosted on the cloud. (Source –Forbes) 74% of Tech CFOs believe that cloud computing will have the greatest impact on their business. (Source – Forbes)
89% of enterprises plan to adopt or have already adopted a digital transformation business strategy with Services (95%), Financial Services (93%) and Healthcare (92%) at the top.
In another study, executives considered digital transformation important for survival in the competitive space. (Source –Forbes) Companies are pushing for digital transformation because it enables an enhanced customer experience, faster time to market and greater innovation.
A study by IDG reveals that 92% of executives consider digital business plans as part of their firm’s strategy. 63% of executives are very close to realizing their digital transformation goals.
Why Businesses Adopt Cloud to Fuel Digital Transformation
Businesses that implement cloud computing and digital transformation report enormous growth and improved efficiency. It enables them to stay relevant and thrive in a dynamic ecosystem. Digital transformation involves finding newer business models. Firms must continuously innovate to stay in the game, and cloud is the catalyst that fuels innovation. As businesses begin to adapt their processes to a digital space, they require cost and work efficiency, elasticity agility and scalability. The cloud provides all of these features.
Here is how the cloud enables digital transformation
1.Agility
A firm has to constantly reinvent its business models. Cloud provides the required infrastructure, platforms and computing abilities that helps firms stay agile and ready for a change.
2. Cost and Labor Effectiveness
Firms don’t have to go to the trouble of investing in and managing the required infrastructure. Cloud computing allows firms to scale up or down, so firms only pay for resources that they use.
3.Security
Moving a database to the cloud offers several advantages of increased protection from threats such as data breaches, disasters, and system shutdown. You can create multiple backups. There is reduced risk of system failure, especially where large amounts of data is involved.
4. Faster Prototyping
Companies follow the cycle of innovating, testing, implementing and repeating. Cloud helps in efficient execution of this process without the need for complicated resources and infrastructure. Hence a company can test and deploy different applications on different platforms during experimentation.
Digital transformation involves replacing legacy systems and traditional work practices with processes that support agility. Files can be made available at any place and at any time. Authority and authentication can be determined for each user, this ensures efficient delegation. There is greater productivity due to collaborative work practices.
The Hybrid Cloud
In spite of its impressive benefits, businesses are moving away from an only public cloud model. A mix of both public and private cloud enables organizations to bring about regulatory compliance, ensure data supremacy, cost optimization, and security. A study by RightScale shows that 85% of firms are using a hybrid cloud strategy.
Hybrid cloud makes faster delivery of apps and services a reality. Firms can combine on-premise systems with an external cloud services provider in a way that provides maximum efficiency. Microsoft has recently introduced the Microsoft Azure Stack, where firms can manage both private and public cloud on a single azure platform
Google also focused solely on the public cloud. Later the hybrid cloud was adopted, with the former VMware CEO Diane Greene steering Google’s cloud strategy. Google’s partnership with Nutanix serves to strengthen the hybrid cloud model. Customers can run applications both on-premise and in the public cloud.
Digital Transformation in Action
Schneider Electric, a leader in the energy management and automation space, uses EcoStruxure Platform as the IoT backbone. It offers:
embedded connectivity and intelligence.
a foundation for smart operations that is interoperable.
A reliable infrastructure for digital services connected to the cloud.
This platform enables faster at scale delivery of IoT-enabled solutions for smart buildings and data centers. It uses Microsoft’s Azure as the cloud framework to offer its digital services and analytics. EcoStruxure closes the gap between IT and OT.
Users are able to utilize the platform to connect equipment and software to the cloud, using IoT technology. Schneider Electric’s EcoStruxure simplifies the process of connecting IoT devices, collection, and analysis of data, and using real-time information to improve operations.
Challenges in Implementing Cloud for Digital Transformation
Data Security and Service Quality
Information, when migrated to the cloud, requires additional security measures. The cloud service provider holds the user’s security and privacy controls, exposing critical information to attack. Poor quality of cloud services also poses a challenge. A possible solution is to retain control of data and enable real-time analysis via dashboards. Performance, scalability, and availability of cloud services are also important factors to consider.
Performance and Costs
Data-intensive applications often result in higher costs. Bandwidth requirements increase when exhaustive and intricate data is sent over the network. Organizations should move to a metered and dynamic pricing model to keep costs down. Cloud service providers must also provide the option to fix costs for each service.
Migrating and integrating Existing Systems
Migrating legacy systems is a cumbersome task. However, with a sufficient budget and organization-wide support, this can be accomplished. The challenge is to integrate the existing infrastructure with the cloud to ensure maximum efficiency and productivity.
Governance
Governance ensures that information and data are used in accordance with agreed upon policies and procedures. IT governance must also align with overarching business goals and objectives. Cloud-based systems offer only partial control over how infrastructure is provided and operated. Hence the need for stringent governance measures.
Cloud is Essential for Advancing Digital Transformation
As the world evolves and tech moves at breakneck speed, digital transformation becomes a means of survival. Cloud becomes the catalyst for this transformation and the hybrid cloud will have a key role to play. In an era where success is measured by customer experience, a cloud-enabled and cloud-delivered business model helps organization discover newer channels to offer a superior customer experience.
Sripathi Krishnan
#Django | 6 Min Read
Share:
In this article post, we will learn how to implement social login in a Django application by using Social auth app Django which happens to be one of the best alternatives of the deprecated library python social auth
What is Social-Auth-App-Django?
Social auth app Django is an open source python module that is available on PyPI. This is maintained under the Python Social Auth organization. Initially, they started off with a universal python module called Python social auth which could be used in any Python-based web framework. However, at the moment they have deprecated this library.
Going further, the code base was split into several modules in order to offer better support for python web frameworks. The core logic of social authentication resides in the social core module, which is then used in other modules like – social auth app django, social app flask, etc.
Installation Process
Let us now create an app called authentication. This app will contain all the views/urls related to Django social authentication.
python manage.py startapp authentication
You will have to make sure that you have created a Django project and then install social-auth-app-django from PyPI.
Now, go to http://localhost:8000/admin and you should see three models under SOCIAL_DJANGO app
Configure Authentication Backend
Now, to use social-auth-app-django’s social login, we will have to define our authentication backends in the setting.py file. Note that although we want to give our users a way to sign in through Google, we also aim to retain the normal login functionality where the username and password can be used to login to our application. In order to do that, configure the AUTHENTICATION_BACKENDS this way:
Note that we have django.constrib.auth.backends.ModelBackend still in our AUTHENTICATION_BACKENDS. This will let us retain the usual login flow.
Template and Template Context Processors
To keep it simple, we will have a plain HTML file which has a link to redirect the user for google+ login.
Go ahead and add a templates’ folder to the authentication app and create a new index.html file in it. In this html file, we will just be putting a simple anchor tag, which will redirect to social-auth-app-django’s login URL
For setting up credentials for other OAuth2 backend, the pattern is like this:
SOCIAL_AUTH__KEY =
SOCIAL_AUTH__SECRET =
Usage
Now that the configuration is done, we can start off using the social login in the Django application. Go to http://localhost:8000 and click the Google+ anchor tag.
It should redirect to Google OAuth screen where it asks you to sign in. Once you sign in through your Gmail account, you should be redirected to the redirect URL.
To check if a user has been created, go to the django admin (http://localhost:8000/admin) and click on the User social auths table. You should see a new user there with the provider as goole-oauth2 and Uid as your gmail id.
Triggering The OAuth URLs from Non-Django Templates
There are chances that you want to trigger the social login URLs from a template that is not going to pass through Django’s template context processors. For instance, when you want to implement the login in an HTML template which is developed in using ReactJS.
This is not as complicated as it looks. Just mention the href in your anchor tag like this:
The login URL for other OAuth providers is of the same pattern. If you are not sure about what the login redirect url should be, there are two ways to find the URL – either jump into their code base or try this hack –
You can create a Django template and place an anchor tag with the respective URL as shown in the Templates and Template context processors section.
You can remove the respective provider (in case of Google oauth2, remove social_core.backends.google.GoogleOAuth2 from the AUTHENTICATION_BACKENDS in settings.py
You can click the anchor tag in a Django template. Doing so, you would see the Django’s regular error template saying “Backend not found”.
Copy the current URL in the browser and use it in your non-Django template.
Summary
We learned what Social auth app Django is and that it uses social core behind the scenes. We also learned how to implement social login in Django through templates that are processed by Django and through non-Django templates, which could be developed using JS frameworks like ReactJS.
Sripathi Krishnan
#Business | 5 Min Read
Share:
At HashedIn, we commonly deploy Django based applications on AWS Elastic Beanstalk. While EB is great, it does have some edge cases. Here is a list of things you should be aware of if you are deploying a Django application.
Aside: If you are starting a new project meant for the elastic beanstalk, Django Project Template can simplify the configuration.
Gotcha #1: Auto Scaling Group health check doesn’t work as you’d think
Elastic Beanstalk lets you configure a health check URL. This health check URL is used by the elastic load balancer to decide if instances are healthy. But, the auto scale group does not use this health check.
So if an instance health check fails for some reason – elastic load balancer will mark it as unhealthy and remove it from the load balancer. However, auto scale group still considers the instance to be healthy and doesn’t relaunch the instance.
Elastic Beanstalk keeps it this way to give you the chance to ssh into the machine to find out what is wrong. If auto scaling group terminates the machine immediately, you won’t have that option.
The fix is to configure autoscale group to use elastic load balancer based health check. Adding the following to a config file under .ebextensions will solve the problem.
Gotcha #2: Custom logs don’t work with Elastic Beanstalk
By default, the wsgi account doesn’t have write access to the current working directory, and so your log files won’t work. According to Beanstalk’s documentation, the trick is to write the log files under the /opt/python/log directory However, this doesn’t always work as expected. When Django creates the log file in that directory, the log file is owned by root – and hence Django cannot write to that file.
The trick is to run a small script as part of .ebextensions to fix this. Add the following content in .ebextensions/logging.config:
With this change, you can now write your custom log files to this directory. As a bonus, when you fetch logs using elastic beanstalk console or the eb tool, your custom log files will also be downloaded.
Gotcha #3: Elastic load balancer health check does not set host header
Django ’s settingALLOWED_HOSTS requires you to whitelist host names that will be allowed. The problem is, elastic load balancer health check does not set hostnames when it makes requests. It instead connects directly to the private IP address of your instance, and therefore the HOST header is the private IP address of your instance.
There are several not-so-optimal solutions to the problem
Terminate health check on apache – for example, by setting the health check URL to a static file served from apache. The problem with this approach is that if Django isn’t working, health check will not report a failure
Use TCP/IP based health check – this just checks if port 80 is up. This has the same problem – if Django doesn’t work, health check will not report a failure
Set ALLOWED_HOSTS = [‘*’] – This disables Host checks altogether, opening up security issues. Also, if you mess up DNS, you can very easily send QA traffic to production.
A slightly better solution is to detect the internal IP address of the server and add it to ALLOWED_HOSTS at startup. Doing this reliably is a bit involved though. Here is a handy script that works assuming your EB environment is Linux:
def is_ec2_linux():
"""Detect if we are running on an EC2 Linux Instance
See http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/identify_ec2_instances.html
"""
if os.path.isfile("/sys/hypervisor/uuid"):
with open("/sys/hypervisor/uuid") as f:
uuid = f.read()
return uuid.startswith("ec2")
return False
def get_linux_ec2_private_ip():
"""Get the private IP Address of the machine if running on an EC2 linux server"""
import urllib2
if not is_ec2_linux():
return None
try:
response = urllib2.urlopen('http://169.254.169.254/latest/meta-data/local-ipv4')
return response.read()
except:
return None
finally:
if response:
response.close()
# ElasticBeanstalk healthcheck sends requests with host header = internal ip
# So we detect if we are in elastic beanstalk,
# and add the instances private ip address
private_ip = get_linux_ec2_private_ip()
if private_ip:
ALLOWED_HOSTS.append(private_ip)
Depending on your situation, this may be more work than you care about – in which case you can simply set ALLOWED_HOSTS to [‘*’].
Gotcha #4: Apache Server on EB isn’t configured for performance
For performance reasons, you want text files to be compressed, usually using gzip. Internally, elastic beanstalk for python uses Apache web server, but it is not configured to gzip content.
Gotcha #5: Elastic Beanstalk will delete RDS database when you terminate your environment
For this reason, always create an RDS instance independently. Set the database parameters as an environment variable. In your Django settings, use dj_database_url to parse the database credentials from the environment variable.
Naureen Razi
#Django | 5 Min Read
Share:
Role Based Access Control provides restrictive access to the users in a system based on their role in the organization. This feature makes the application access refined and secure.
Django provides authentication and authorization features out of the box. You can use these features to build a Role Based Access Control. Django user authentication has built-in models like User, Group, and Permission. This enables a granular access control required by the application.
Here Are Some Build-In Models
User Objects: Core of Authentication
This model stores the actual users in the system. It has basic fields like username, password, and email. You can extend this class to add more attributes that your application needs. Django user authentication handles the authentication through session and middlewares.
With every request, Django hooks a request object. Using this, you can get the details of the logged in user through request.user. To achieve role-based access control, use the request.user to authorize user requests to access the information.
Groups: Way of Categorizing Users
These are logical groups of users as required by the system. You can assign permissions and users to these groups. Django provides a basic view in the admin to create these groups and manage the permissions.
The group denotes the “role” of the user in the system. As an “admin”, you may belong to a group called “admin”. As a “support staff”, you would belong to a group called “support”.
Permission: Granular Access Control
The defined groups control access based on the permissions assigned to each group. Django allows you to add, edit, and change permissions for each model by default.
You can use these permissions in the admin view or in your application. For example, if you have a model like ‘Blog’.
Each of these models is registered as ContentType in Django. All of the permissions that Django creates underclass Permission will have a reference to this specific ContentType. In this case, the following permissions will be created by default:
add_blog: Any User or group that has this permission can add a new blog. change_blog: Any user or group that has this permission can edit the blog. delete_blog: Any user or group that has this permission can delete a blog.
Adding Custom Permissions
Django default permissions are pretty basic. It may not always meet the requirements of your application. Django allows you to add custom permissions and use them as you need. With a model meta attribute, you can add new permissions:
Class Blog(models.Model):
…
Class Meta:
permissions = (
("view_blog", "Can view the blog"),
("can_publish_blog", "Can publish a blog"),
)
These extra permissions are created along with default permissions when you run manage.py, migrate.
How To Use These Permissions
You can assign permission to a user or a group. For instance, you can give all the permissions to the group “admin”. You can ensure that the “support” group gets only the “change_blog” permission. This way only an admin user can add or delete a blog. You need Role-Based Access control for this kind of permission in your views, templates or APIs.
Views:
To check permissions in a view, use has a _perm method or a decorator. The User object provides the method has_perm(perm, obj=None), where perm is “.” and returns True if the user has the permission.
user.has_perm(‘blog.can_publish_blog”)
You can also use a decorator ‘permission_required(perm, login_url=None, raise_exception=False)’. This decorator also takes permission in the form “.”. Additionally, it also takes a login_url which can be used to pass the URL to your login/error page. If the user does not have the required permission, then he will be redirected to this URL.
from Django.contrib.auth.decorators import permission_required
@permission_required(‘blog.can_publish_blog’, login_url=’/signin/’) def publish_blog(request): …
If you have a class-based view then you can use “PermissionRequiredMixin”. You can pass one or many permissions to the permission_required parameter.
from Django.contrib.auth.mixins import PermissionRequiredMixin
class PublishBlog(PermissionRequiredMixin, View): permission_required =blog.can_publish_blog’
[/et_pb_text][et_pb_text admin_label=”Templates:” _builder_version=”3.0.86″ background_layout=”light”]
Templates:
The permissions of the logged in user are stored in the template variable. So you can check for a particular permission within an app.
Level of Access Control: Middleware Vs Decorator
A common question that plagues developers:“Where do I put my permission check, decorator or middleware?”. To answer this question, you just need to know if your access control rule is global or specific to a few views.
For instance, imagine you have two access control rules. The first states that all the users accessing the application must have “view_blog” permission. As per the second rule, only a user having a permission “can_publish_blog” can publish a blog.
In the second case, you can add the check as a decorator to the”publish_blog” view.
In case of former, you will put that check in your middleware as it applies to all your URLs. A user who does not have this permission cannot enter your application. Even if you add it as a decorator, the views are safe.
But adding the decorator to every view of your application would be cumbersome. If a new developer forgets to add the decorator to a view he wrote, the rule gets violated.
Therefore, you should check any permission that’s valid globally in the middleware.
Summary
Thus, you can use Django user authentication to achieve complete role-based access control for your application. Go ahead and make the most of these features to make your software more secure.
Sripathi Krishnan
#Technology | 4 Min Read
Share:
Authenticating REST APIs calls for selecting the right one that suits your application. There are several ways:
Use Case 1. API for Single Page Application
There are two choices for Single Page Applications:
Session Based
Token-Based authentication
The set of questions that need to be asked are:
Should the sessions be invalidated before they expire? If Yes, Sessions must be preferred.
Should the session end based on inactivity as against ending after a fixed time? If Yes, Sessions must be preferred.
Should the me functionality be remembered? If Yes, Sessions must be preferred./li>
Will mobile applications to use the same APIs? If yes, prefer token-based authentication (but ensure a separate API is built for these use cases)
Is Your web framework protected against CSRF? Prefer token based authentication if it is a “No” or if you don’t know what CSRF is.
If token-based authentication is preferred, avoid JSON Web Tokens. JWT should be used as a short, one-time token, as against something that is reused multiple times. Alternatively, you could create a random token, store it in Redis/Memcached, and validate it on every request.
Use Case 2. API for Mobile Apps
Prefer token-based authentication. Mobile apps do not automatically maintain and send session cookies. Hence it would be far easier for a mobile app developer to set an authentication token as opposed to setting a session cookie. Signature-based mechanisms too aren’t useful as secret keys cannot be embedded in a mobile application. Only when you have another channel, say a QR code, to pass secrets, you could use signature-based mechanisms. A random token stored in Redis or Memcached is the most ideal approach. Ensure you use a cryptographically secure random generator in your programming.
Use Case 3. Building a Service that will be Used by Server Side Code Only
The three choices for APIs that are called from a server-side application includes:
Basic authentication over https
Token-based authentication
Signature-based authentication
Will the API be used only internally and only by the applications you control, are the API themselves of low value? If yes, as long as you are using HTTPS, basic authentication is acceptable.
Would you want the keys to be long-lived? If yes, since the keys themselves are never sent over the wire, signature-based authentication.
Would you want the same APIs to be used for both mobile and web apps? If yes, since signature based auth requires clients to store secrets, prefer token-based authentication.
Are you using OAuth? If yes, the decision is made for you. OAuth 1 uses signature-based authentication, whereas OAuth 2 uses token-based authentication.
Do you provide a client library to access your APIs? If yes, prefer signature based auth, because you can then write the cryptography code once and provide it to all your clients.
Use Case 4. Using JSON Web Tokens
JWT works best for single use tokens. Ideally, a new JWT must be generated for each use. Acceptable use cases:
Server-to-server API calls, where the client can store a shared secret and generate a new JWT for each API call.
Generate links that expire shortly – such as those used for email verification
As a way for one system to provide a logged in user limited access to another system.
Use Case 5. OAuth for APIs
OAuth should be used, only if the below criteria are met:
The Consumers or the user-specific data is exposed by your API
Some of the user-specific data is being accessed by third-party developers that you don’t trust
If You want to ask your users if they want to share their data with the third party developer
If the answer is “yes” to ALL the 3 questions, you certainly require OAuth.
Use Case 6. Compare all the Different Authentication Techniques
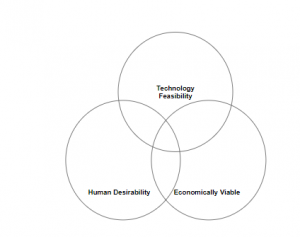
As Tim Brown (the CEO of IDEO) beautifully puts “Design thinking is a human-centered approach to innovation that draws from the designer’s toolkit to integrate the needs of people, the possibilities of technology, and the requirements for business success.”
The importance of design has been constantly increasing over the years. The consumers of today’s generation have quick access to the global marketplaces. They do not distinguish between physical and digital experiences anymore.
This has made it difficult for companies to make their products or services stand out from the rest of the competitors.
Infusing your company with a design-driven culture that puts the customer first may not only provide real and measurable results but also give you a distinct competitive advantage.
All the firms that have embraced a design-driven culture have certain things in common.
First, these firms consider design more than a department. Firms that primarily focus on design tries to encourage all functions to focus more on their customers.
By doing this, they are also conveying a message that design is not a single department, in fact, design experts are everywhere in an organization working in cross-functional teams and having constant customer interaction.
Second, for such companies, the design is much more than a phase. Popular design-driven companies use both qualitative and quantitative research during the early product development phase, bringing together techniques such as ethnographic research and in-depth data analysis to clearly understand their customers’ needs.
Why Design Thinking?
Thinking like a designer can certainly transform the way companies develop products/services, strategies, and processes.
If companies can bring together what is most desirable from a human point of view with what is technologically feasible and also economically viable, they can certainly transform their businesses.
This also gives an opportunity to people who are not trained as designers to utilize creative tools to tackle a range of challenges.
Design Thinking Approach
Empathize: Understand your users as clearly as possible and empathize with them.
Define: Clearly define the problem that needs to be sorted and bring out a lot of possible solutions.
Ideate: Channel your focus on the final outcomes, not the present constraints.
Prototype: Use prototypes for exploring possible solutions.
Test: Test your solutions, reflect on the results, improvise the solution, and repeat the process. (Recently, we had Mr. Ashish Krishna (Head of Design – Prysm) addressing our interns about the same Design Thinking Approach )
Facts that prove the importance of having a Design Thinking Approach
Some years ago, Walmart had revamped its e-commerce experience, and as a result, the unique visitors to its website increased by a whopping 200%. Similarly, When BOA (Bank of America) undertook a user-centered design of its process for the account registrations, the online banking traffic shot up by 45%.
In a design-driven culture, firms are not afraid to launch a product that is not totally perfect, which means, going to market with an MVP (minimally viable product), learn from the customer feedback, incorporate the same, and then build and release the next version of the product.
A classic example of this is Instagram, which launched a product, learning which features were most popular, and then re-launching a new version. As a result, there were 100,000 downloads in less than a week.
ROI from Design
Let’s take a look at some examples of how design impacted the ROI of companies.
The Nike – Swoosh, which is one of the most popular logos across the globe, managed to sell billions of dollars of merchandise through the years. The icon was designed in the year 1971 and at that time the cost was only $35. However, after almost 47 years, that $35 logo evolved into a brand, which Forbes recently estimated to be worth over $15 billion.
Some years back the very popular ESPN.com received a lot of feedback from users for their cluttered and hard to navigate homepage. The company went ahead and redesigned their website, and as a result, the redesign garnered a 35% increase in their site revenues.
Some Benefits of having a Design Thinking Approach
Helps in tackling creative challenges: Design thinking gives you an opportunity to take a look at problems from a completely different perspective. The process of design thinking allows you to look at an existing issue in a company using creativity.
The entire process will involve some serious brainstorming and the formulation of fresh ideas, which can expand the learner’s knowledge. By putting design thinking approach to use, professionals are able to collaborate with one another to get feedback, which thereby helps in creating an invaluable experience to end clients.
Helps in effectively meeting client requirements: As design thinking involves prototyping, all the products at the MVP stage will go through multiple rounds of testing and customer feedback for assured quality.
With a proper design thinking approach in place, you will most likely meet the client expectations as your clients are directly involved in the design and development process.
Expand your knowledge with design thinking: The design process goes through multiple evaluations. The process does not stop even after the deliverable is complete.
Companies continue to measure the results based on the feedback received and ensure that the customer is having the best experience using the product.
By involving oneself in such a process, the design thinkers constantly improve their understanding of their customers, and as a result, they will be able to figure out certain aspects such as what tools should be used, how to close the weak gaps in the deliverable and so on.
Conclusion
If we take a closer look at a business, we will come to a realization that the lines between product/services and user environments are blurring. If companies can bring out an integrated customer experience, it will open up opportunities to build new businesses.
Design thinking is not just a trend that will fade away in a month. It is definitely gaining some serious traction, not just in product companies, but also in other fields such as education and science.
Sripathi Krishnan
#Django | 24 Min Read
Share:
Designing Modules in Python is part of HashedIn’s training program for junior developers to get better at design. Today, we are making it available as a free ebook.
This book is for all those who have some experience in an object-oriented programming language. If you wish to get better at the module or class level design, then this book is definitely for you. You will be able to identify a good design from the bad after you finish reading this book All throughout this book, python is used to introduce various design patterns. However, the knowledge of python is not mandatory. If you can understand classes and methods, you will easily be able to understand the contents of this book
How to use this book
To make the most of this book, read the requirements at the start of each chapter and write down your solution. Then read through the rest of the chapter and critique your solution. Good design is obvious once presented. However, arriving at that solution is difficult, especially if you are new to programming. Writing down your solution is the only way to realize the shortcomings of your design. If you read the chapter without writing, you will tell yourself “That was obvious. I would have solved it in a similar manner”
History of this book
At HashedIn, we conduct a training program for junior developers to get better at design. During one of these programs, we asked developers to design a module to send SMS/text messages. We also asked them to call the SMS module from 3 different client applications. They had 30 minutes to complete this activity. After 30 minutes, we revealed a new set of requirements. Additionally, we set 2 hard rules for them to implement these requirements:
Developers were not allowed to change the way client applications invoked their SMS module
Developers were not allowed to modify existing code. Instead, they had to write new code to address the additional requirements, without duplicating code.
20 minutes later, we again introduced a new set of requirements. And after another 20 minutes, we introduced the final set of requirements. Initially, the developers felt the problem was very simple. They were at loss to understand why the design was even needed. Isn’t this a simple python function? But as new requirements emerged, and because we gave them constraints (don’t change existing code) – they began to appreciate the various design principles. Some even developed a mental model to discern good design from bad. Over time, we got the opportunity to review designs from several developers. We learned how junior developers think when asked to solve a problem. Based on these patterns, we wrote a series of blogs on how to design modules in python.
Design Modules in Python
Python Interface Design
The first module will teach you as to how you can design a reusable python module. By the end of the post, you will get a great understanding of writing reusable and extensible modules in python.
You have been given the following requirements:
You are the developer on Blipkart, an e-commerce website. You have been asked to build a reusable SMS module that other developers will use to send SMS’es. Watertel is a telecom company that provides a REST API for sending SMS’es, and your module needs to integrate with Watertel. Your module will be used by other modules such as logistics.py and orders.py.
The first goal for a module should be good Abstraction. Your module sits between client developers on one side, and the API provided by Watertel on the other side. The module’s job is to simplify sending an SMS, and to ensure that changes in Watertel do not affect your client developers.
The essence of abstractions is preserving information that is relevant in a given context, and forgetting information that is irrelevant in that context.
Watertel exposes these concepts – username, password, access_token and expiry, phone number, message, and priority. Which of these concepts are relevant to client developers?
Client developers don’t care about username and password. They don’t want to worry about expiry either. These are things our module should handle. They only care about phone number and message – “take this message, and send it to this phone number”.
Interface Design
Since developers only care about phone_number and message, our interface design is very clear – we need a send_sms(phone_number, message) function. Everything else is irrelevant.
Now, looking from an implementation perspective. We need the URL, the username, and password. We also need to manage the access token and handle its expiry. How will we get this information? Let’s carve out an interface design for our solution.
In general, if you need some information, or if you depend on other classes – you must get it via your constructor. Your class must not go about trying to find that information on its own (say from Django settings).
Here’s how our interface looks like:
# sms.py:
class SmsClient:
def __init__(self, url, username, password):
self.username = username
self.password = password
def send_sms(phone_number, message):
# TODO - write code to send sms
pass
Using our Class in Client Code
Next, in order to use our module, our clients need an object of SmsClient. But in order to create an object, they’d need username and password. Our first attempt would be something like this:
# In orders.py
from django.conf import settings
from sms import SmsClient
sms_client = SmsClient(settings.sms_url, settings.sms_username, settings.sms_password)
....
sms_client.send_sms(phone_number, message)
There are two problems with this:
First, orders.py shouldn’t care how SmsClient objects are constructed. If we later need additional parameters in the constructor, we would have to change orders.py, and all classes that use SmsClient. Also, if we decide to read our settings from someplace else (say for test cases), then orders.py would have to be modified.
The second problem is that we would have to create SmsClient objects everywhere we want to use it. This is wasteful, and also leads to code duplication.
The solution is to create SmsClient object in sms.py module [see footnote 1]. Then orders.py and logistics.py can directly import the object from SMS. Here is how it looks.
# In sms.py:
from django.conf import settings
class SmsClient:
def __init__(self, url, username, password):
self.username = username
self.password = password
def send_sms(phone_number, message):
# TODO - write code to send sms
pass
sms_client = SmsClient(settings.sms_url, settings.sms_username, settings.sms_password)
and in orders.py:
# orders.py
from sms import sms_client
...
# when you need to send an sms
sms_client.send_sms(phone_number, message)
Before you start implementing, think about how your clients will use your module. It’s a good idea to actually write down the client code (i.e. code in orders.py and logistics.py) before you start implementing your module.
Next step is to learn as to how python design patterns can be benefited from dependency injection.
Here we discuss how python module designing be benefited from dependency injection. You have been given the following requirements:
You are the developer on Blipkart, an e-commerce website. You have been asked to build a reusable SMS module that other developers will use to send SMS’es. Watertel is a telecom company that provides a REST API for sending SMS’es, and your module needs to integrate with Watertel. Your module will be used by other modules such as logistics.py and orders.py.
The client modules have a dependency on our module to complete a portion of its work which is – sending an SMS. So our module’s object has to be injected in the client’s module through the respective modules do not know each other directly.
Why Dependency Injection?
The essence of dependency injection is that it allows the client to remove all knowledge of a concrete implementation that it needs to use. This helps isolate the client from the impact of design changes and defects. It promotes reusability, testability and maintainability.
Basically, instead of having your objects creating a dependency or asking a factory object to make one for them, you pass the needed dependencies into the object externally, and you make it somebody else’s problem. This “someone” is either an object further up the dependency graph, or a dependency injector (framework) that builds the dependency graph. A dependency as I’m using it here is any other object the current object needs to hold a reference to.
The client modules ie. orders.py and logistics.py can import our module’s object and then inject it where it needs the module to perform its task.
This will explain how it should look like.
# In sms.py:
from django.conf import settings
class SmsClient:
def __init__(self, url, username, password):
self.username = username
self.password = password
def send_sms(phone_number, message):
# TODO - write code to send sms
pass
sms_client = SmsClient(settings.sms_url, settings.sms_username, settings.sms_password)
and in orders.py:
# orders.py
from sms import sms_client
...
# when you need to send an sms
sms_client.send_sms(phone_number, message)
How does Dependency Injection help us?
1. Dependency Injection decreases coupling between a class and its dependency.
2.Because dependency injection doesn’t require any change in code behavioDependencybe applied to legacy code as a refactoring. The result is clients that are more independent and that are easier to unit test in isolation using stubs or mock objects that simulate other objects not under test. This ease of testing is often the first benefit noticed when using dependency injection.
3. To free modules from assumptions about how other systems do what they do and instead rely on contract.
4. To prevent side effects when replacing a module.
So in all, dependency injection is a great practice to make our modules more testable, maintainable and scalable and we should use it more often to make our lives easier as developers.
Exception Handling In Python
Now we will have a detailed discussion on the Exception Handling in Python. We will discuss in detail, the implementation of a robust SMS module.
To start sending SMS’es, we need to first login to Watertel, store the accessToken and the time when the accessToken expires.
# sms.py
class SmsClient:
def __init__(self, url, username, password):
self.url = url
self.username = username
self.password = password
self.access_token = None
self.expires_at = 0
def _login(self):
# TODO - Make HTTPS request, get accessToken and expiresAt
# TODO - error handling, check status codes
self.access_token = response["accessToken"]
self.expires_at = get_current_time() + response["expiry"]
You don’t expect or want client developers to think about login, hence we make the login method private (start with the underscore). Now we need to decide who calls the _login method. One easy (and wrong) choice, is calling the _login method from our constructor. Constructors must not do real work, but only aid in initialization. If we make network calls in the constructor, it makes the object difficult to test, and difficult to reuse. So _login cannot be called by clients, and cannot be called in the constructor. Which leaves us with only one choice – call _login from the send_sms method. And while we are at it, we will add another wrapper to directly get us the access_token without worrying about expiry. This also gives the necessary modularity to our code.
def _get_access_token(self):
if (get_current_time() > self.expires_at):
self._login()
return self.access_token
def send_sms(self, phone_number, message):
access_token = self._get_access_token()
# TODO: use the access_token to make an API call and send the SMS
At this point we can start writing code to send the SMS. We will assume a make_request function that returns the parsed JSON object and the http status code.
What should we do with the status_code? One option is to return the status_code and let our clients handle it. And that is a bad idea. We don’t want our clients to know how we are sending the SMS. This is important – if the clients know how you send the SMS, you cannot change how your module works in the future. When we return the HTTP status code, we are telling them indirectly how our module works. This is called a leaky abstraction, and you want to avoid it as much as possible (though you can’t eliminate it completely). So to give our code the much-needed abstraction, we will not return the status code, but we still want our clients to do some error handling. Since our clients are calling a python method, they expect to receive errors the pythonic way – using Exception Handling in Python. When it comes to error handling, you need to be clear whose problem it is. It’s either the client developer’s fault or your module’s fault. A problem with your module’s dependency (i.e. Watertel server down) is also your module’s fault – because the client developer doesn’t know Watertel even exists. We will create an exception class for each possible error in the module –
BadInputError – a base error for incorrect inputs
InvalidPhoneNumberError – when the phone number is malformed or wrong
InvalidMessageError – when the message is longer than 140 characters
SmsException – when it’s our modules fault and we cannot send the SMS. This tells our clients that calling send_sms again is safe and may work.
On implementing python exception handling, here is how our code looks like:
def _validate_phone_number(self, phone_number):
if not phone_number:
raise InvalidPhoneNumberError("Empty phone number")
phone_number = phone_number.strip()
if (len(phone_number) > 10):
raise InvalidPhoneNumberError("Phone number too long")
# TODO add more such checks
def _validate_message(self, message):
if not message:
raise InvalidMessageError("Empty message")
if (len(message) > 140):
raise InvalidMessageError("Message too long")
def send_sms(self, phone_number, message):
self._validate_phone_number(phone_number)
self._validate_message(message)
access_token = self._get_access_token()
status_code, response = _make_http_request(access_token, phone_number, message)
if (status_code == 400):
# This is Watertel telling us the input is incorrect
# If it is possible, we should read the error message
# and try to convert it to a proper error
# We will just raise the generic BadInputError
raise BadInputError(response.error_message)
elif (status_code in (300, 301, 302, 401, 403)):
# These status codes indicate something is wrong
# with our module's logic. Retrying won't help,
# we will keep getting the same status code
# 3xx is a redirect, indicate a wrong url
# 401, 403 have got to do with the access_token being wrong
# We don't want our clients to retry, so we raise RuntimeError
raise RuntimeError(response.error_message)
elif (status_code > 500):
# This is a problem with Watertel
# This is beyond our control, and perhaps retrying would help
# We indicate this by raising SmsException
raise SmsException(response.error_message)
Error Handling in Python – Exceptions
Apart from error handling of status codes, there’s one more thing that is missing – handling any exceptions that are raised by _make_request. Assuming you are using the wonderful requests library, this is the list of exceptions that can be thrown. You can categorize these exceptions into two categories – safe to retry v/s not safe to retry. If it is safe to retry, wrap the exception in a SMSException and raise it. Otherwise, just let the exception propagate. In our case, ConnectTimeout is safe to retry. ReadTimeout indicates the request made it to the server, but the server did not respond timely. In such cases, you can’t be sure if the SMS was sent or not. If it is critical the SMS be sent, you should retry. If your end users would be annoyed receiving multiple SMSes, then do not retry. You can handle these exceptions inside the _make_request method.
This should have given you a gist of how exception handling in python can help build a cleaner and more robust code. That covers most of the implementation of our module. We won’t get into the code that actually makes the HTTP request – you can use the requests library for that.
So,
Don’t leak inner workings of your module to your clients, otherwise, you can never refactor or change your implementation.
Raise appropriate Errors to inform your clients about what went wrong.
Open Closed Principle in Python
The open/closed principle teaches us not to modify our already working code just for adding new features.
New Requirements – Retry Failed SMS’es
We now have a feature request from the product managers:
Customers are complaining that they don’t receive SMS’es at times. Watertel recommends resending the SMS if the status code is 5xx. Hence we need to extend the sms module to support retries with exponential backoff. The first retry should be immediate, the next retry within 2s, and the third retry within 4s. If it still continues to fail, give up and don’t try further.
Of course, our product manager assumed we would take care of a few things, viz
We will implement this in all of the 50 modules that are sending SMS’es.
There would be no regression bugs due to this change.
Don’t modify the code that’s already working
Let’s start planning our change. There are two seemingly opposing views here. We don’t want client developers to change their code, not even a single character. At the same time, the SmsClient class we wrote in part IIworks great – and we don’t want to change the code that is already working either. A little aside – let’s look at the open/closed principle. The open/closed principle tells us that we should not modify existing source code just to add new functionality. Instead, we should find ways to extend it without modifying the source code. It is a part of the SOLID Programming Principles. In fact, it stands for the ‘O’ in the SOLID principles. In our case, the open/closed principle implies that we don’t want to touch the source code for SmsClient.
Using Inheritance
This is a tricky situation, but as with everything else in software, this problem can be solved with a little bit of indirection. We need something sitting in between our clients and our SmsClient class. That something can be a derived class of SmsClient.
# This is the class we wrote in Part III
# We are not allowed to change this class
class SmsClient:
def send_sms(self, phone_number, message):
...
class SmsClientWithRetry(SmsClient):
def __init__(self, username, password):
super(SmsClient, self).__init__(username, password)
def send_sms(self, phone_number, message):
# TODO: Insert retry logic here
super(SmsClient, self).send_sms(phone_number, message)
# TODO: Insert retry logic here
# Earlier, client was an instance of SmsClient, like this
# client = SmsClient(username, password)
# We now change it to be an instance of SmsClientWithRetry
# As a result, our client developers doesn't have to change
# They are simply importing client from sms.py
client = SmsClientWithRetry(username, password)
If you notice, using inheritance, we got ourselves a way to add retry logic without modifying the existing code that is already known to work. This is the crux of the open/closed principle. See Footnotes for a caveat on using inheritance.
Adding Retry Logic
With that done, we can now work on adding the retry logic. We don’t want to retry if our client gave us an invalid phone number or a bad message – because it is a waste of resources. Even if we retried 100 times, it won’t succeed. We also don’t want to retry if there is a logic problem in our module’s code – because our code cannot fix itself magically, and hence, retry is unlikely to help. In other words, we only want to retry if Watertel has a problem and we believe retrying may end up delivering the message.
If you revisit our original SmsClient implementation, you will now appreciate the way we designed our exceptions. We only want to retry when we get a SmsException. We simply let the client developers deal with all the other exception types.
How do we go about writing the retry loop? The best way to write the retry logic is via a decorator. It’s been done so many times in the past, that it’s best I point you out to some libraries.
Thus, the open/closed principle tells us not to modify our already working code just to add new features. It’s okay to change the code for bug fixes, but other than that, we should look at functional/object-oriented practices to extend the existing code when we want to add new functionalities. Thus, we saw how the application of the SOLID programming principle and the open/closed principle in specific helped us to manage retries in our system.
A Tip: In general, we should prefer composition over inheritance.
Inheritance versus Composition in Python
We will now compare the inheritance and composition to determine better ways to reuse the existing code.
We now have new requirements for our product managers:
To increase the reliability of our SMSes, we would like to add Milio to our SMS providers. To start with, we want to use Milio only for 20% of the SMSes, the remaining should still be sent via Watertel. Milio doesn’t have a username/password. Instead, they provide an access token, and we should add the access token as a HTTP header when we make the post request.
Of course, like last time around
We do not want to change existing code that is already working.
We need to have the retry logic for Milio as well.
Finally, we do not want to duplicate any code.
Creating an Interface
The first obvious step is to create a new class MilioClient, with the same interface as our original SmsClient. We have covered this before, so we will just write the pseudo-code below.
class MilioClient:
def __init__(self, url, access_token):
self.url = url
self.access_token = access_token
def send_sms(self, phone_number, message):
# Similar to send_sms method in SmsClient
# Difference would be in the implementation of _make_request
# We will have different JSON response,
# and different request parameters
print("Milio Client: Sending Message '%s' to Phone %s"
% (message, phone_number))
Some discussion points –
Should MilioClient extend SmsClient? No. Though both are making network calls, there isn’t much commonality. The request parameters are different, the response format is different.
Should MilioClient extend SmsClientWithRetry? Maybe. Here, the retry logic is reusable and common between the two. We can reuse that logic using inheritance, but it isn’t the right way to reuse. We will discuss this a little later in this post.
Inheritance versus Composition
The reason why we can’t inherit the SmsClientWithRetry class is that the constructor of this class expects a username and password. We don’t have that for Milio. This conflict is large because we made a mistake in the earlier chapter – we chose to build new logic using inheritance. Better late than never. We will refactor our code and this time, we will use Composition instead of Inheritance.
# We rename SmsClient to WatertelSmsClient
# This makes the intent of the class clear
# We don't change anything else in the class
class WatertelSmsClient(object):
def send_sms(self, phone_number, message):
...
# This is our new class to send sms using Milio's APi
class MilioSmsClient(object):
def send_sms(self, phone_number, message):
...
class SmsClientWithRetry(object):
def __init__(self, sms_client):
self.delegate = sms_client
def send_sms(self, phone_number, message):
# Insert start of retry loop
self.delegate.send_sms(phone_number, message)
# Insert end of retry loop
_watertel_client = SmsClient(url, username, password)
# Here, we are passing watertel_client
# But we could pass an object of MilioClient,
# and that would still give us retry behaviour
sms_client = SmsClientWithRetry(_watertel_client)
The logic to Split Traffic
Now let’s look at the next requirement – how do we split the traffic between the two implementations? The logic is actually simple. Generate a random number between 1 and 100. If it is between 1 and 80, use WatertelSmsClient. If it is between 81 and 100, use MilioSmsClient. Since the number is random, over time we will get an 80/20 split between the implementations.
Introducing a Router class
Now that we have retry logic for Milio in place, let’s face the elephant in the room – where should we put this logic? We cannot change the existing client implementations. And of course, we can’t put this logic in MilioSmsClient or WatertelSmsClient – that logic doesn’t belong there. The only way out is one more indirection. We create an intermediate class that is used by all existing clients. This class decides to split the logic between MilioSmsClient and WatertelSmsClient. Let’s call this class SmsRouter.
class SmsRouter:
def send_sms(self, phone_number, message):
# Generate random number
# Between 1-80? Call send_sms method in SmsClient
# Between 80-100? Call send_sms method in MilioClient
pass
Providing Concrete Implementations to SmsRouter
Our SmsRouter needs instances of SmsClient and MilioClient. The easiest way is for SmsRouter to create the objects in the constructor.
If you feel the code is ugly, you are not alone. But why is it ugly? We are passing 6 parameters to the constructor, and are constructing objects in the constructor. If these classes require new parameters, our constructor will also change To remove this ugliness, we pass fully constructed objects to SmsRouter, like this:
Eeks. We again went up to four parameters. Again, why is this ugly? SmsRouter doesn’t really care about the difference between milio or watertel, but it still has variables with those names.
Generalizing SmsRouter
Let’s generalize it by passing a list of sms providers.
class SmsRouter:
def __init__(self, providers):
'''Providers is a list of tuples, each tuple having a provider and a percentage
providers = [(watertel, 80), (milio, 20)]'''
self.providers = providers
def _pick_provider(self):
# Pick up a provided on the basis of the percentages provided
# For now, we will pick a random one
return self.providers[randint(0, 1)][0]
def send_sms(self, phone_number, message):
provider = self._pick_provider()
provider.send_sms(phone_number, message)
With this version of SmsRouter, we can now provide multiple implementations, and the router will intelligently delegate to the right router.
Using our SmsRouter
This is how we can now use the router:
# First, create the concrete implementations
watertel = SmsClient("https://watertel.example.com", "username", "password")
milio = MilioClient("https://milio.example.com", "secret_access_token")
# Create a router with an 80/20 split
sms = SmsRouter([(watertel, 80), (milio, 20)])
# Calling the send_sms in a loop will on an average
# send the messages using the percentages provided
for x in range(1, 10):
sms.send_sms("99866%s" % (x * 5, ), "Test message %s" % x)
So why composition over inheritance?
Object composition has another effect on system design. Favoring object composition over inheritance helps you keep each class encapsulated and focused on one task. Your classes and class hierarchies will be small and will be less likely to grow into unmanageable monsters.
Also, we were able to add additional functionality without modifying the existing code. This is an example of composition – wrapping existing functionality in powerful ways.
Organizations who proactively see and act upon the opportunities for change through innovation in a highly volatile business environment will not only survive but will also successfully flourish in the toughest of the economic conditions.
Such companies will use innovation as a technological and a strategic tool to develop agile innovation culture and effective business processes.
With companies taking such bold steps, it will enable them to achieve certain key business outcomes such as:
Maximizing their Return on Investment to shareholders
Effectively achieving business growth goals
Increasing the productivity and thereby increasing the profitability
Effectively responding to industry disrupters and increasing market share
Quickly responding to the external challenges by developing human as well as technological resources to do things differently
Here are some ways to make innovation a strategic tool to transform businesses and for overall sustainability.
It is also a powerful tool that enables people to affect the business breakthroughs and also deliver a profound process, a solid system, and culture.
As a result, there would be increased business engagement, competitiveness, and rapid business growth to enable the business to flourish in this current age of disruption.
Effectively responding to unforeseen events
Being innovate means being willing and competent in knowing how to think and act differently. It is important to know how to think analytically and know how to think at critical levels.
It is also critical to foresee and solve challenges and respond to unprecedented events and external crises in different ways and transform them into creative and innovative solutions that people love and cherish.
Solving complex challenges
One of the main things that one needs to understand about innovation is that it is about how companies perceive and solve challenges in creative ways. There is a need for a sense of urgent passionate purpose to solve complex problems so as to improve the quality of people’s lives and the way we live.
Capitalizing on the global entrepreneurship movement
Currently, the entrepreneurship is a global movement, it is now growing in emerging markets, where countries like China and India are leading the pack. Governments have come to a realization that entrepreneurship is a tool of economic success and have now started backing and supporting entrepreneurs. Innovation enables entrepreneurship and it also empowers people to take complete control of their lives and create their own destiny.
Competing with lean & agile startup methodologies
Every business goes through a rough patch at some point or the other. However, what is really important is making some really effective strategic moves that help in discovering new and unexplored markets.
Lately, many new businesses are slowly shifting towards using certain strategies that incorporate lean as well as agile methodologies as a way of innovating businesses for creating increased value for customers that they value.
Catching up with advances in technology
The advancement of digitization, which is enabled by the IoT has synced the connection and sharing of information between multiple digital devices.
It is because of this connectivity and aggregation of data that more revenue streams are getting created, both for new as well as established firms that leverage existing asset in exciting and profitable ways.
It is also changing the basis of competition as companies will now be able to compete as part of the ecosystems. The increasing availability, as well as accessibility to free and low cost online education, is encouraging and enabling almost everyone with a desire for learning. There is a hunger for knowledge to become subject matter experts in their fields.
Innovative entrepreneurs are expanding their business with the internet of things, fully connected mobile devices, cloud computing and via the social media. Especially by developing software applications that are aimed to improve the quality of people’s lives across the globe.
Adapting to evolving workplace dynamics and trends
At present, millennials are swapping jobs at increasing rates as they seek more meaningful work and equality. Recruitment processes are also shifting as a lot of recruiters are mostly relying on online-based social processes where reputation is becoming extremely important to professionals and organizations.
Freelancing and contracting are also becoming a way of life, a number of people are working from home and taking responsibility for generating own income and wealth.
They are also operating more from coworking and collaborative work environments, which means to say that they are networking as well as teaming up to share and gain knowledge and experience.
These are some of the factors that are forcing companies to explore innovative strategies to enhance staff engagement, empowerment, acquisition and retention of the best resources.
Responding to increasing customer expectations and choices
Major changes are required on how companies perceive their customer’s needs and expectations as they are also empowered by the increasing speed and the wide range of choices available in the strongly connected and digitized world.
Their focus is on getting the value that demonstrates that companies understand as well as empathize with them and even support their lifestyle choices. Increasing consumer expectations, as well as choices, are majorly impacting companies to become more customer-centric via innovative change.
By using human-centered design to improve the user experience, companies can effectively create and invent products and services that people value and cherish.
Maximizing globalization connectivity
Currently, the globalization has been driven by policies. This has opened economies locally and internationally, and as a result, many governments are now adopting free-market economic systems, hugely increasing their own productive potential and creating fresh opportunities for international trade.
They are also reducing the barriers to global trade and bringing in new global agreements for promoting trade in goods, services, and investments.
This trend enables true connectivity as well as collaboration to occur. People are now encouraged to develop an internet-based business that helps them using application of lean methodologies.
People are starting low-cost, online-based businesses because of the increasing availability of private funding and simplification of compliance factors and government infrastructures.
Being highly passionate and having an immense necessity making innovation a strategic and powerful tool to impact business breakthroughs, growth and competitiveness enable companies to prosper in this age of disruption.
Many companies in the future will use innovation as a disruptive mechanism to completely outperform its competitors and venture new markets by enhancing customer experiences.
Pansul Bhatt
#Django | 19 Min Read
Share:
This is the seventh post on the Django blog series. In this post we will learn on how we can optimize the django application’s performance. The inspiration of this post has mainly been, the performance improvement of Charcha Discussion Forum. The source code for the charcha forum is available here.
For this post, like all preceding posts in this series, we are going to use Charcha’s codebase as an example and try to optimize the pages from there on out. Also, as the range for optimization is exceedingly high we would try to tackle all the domains one by one. The main focus would be to attain maximum proficiency in the backend (as it is a django application at the end of the day) and the measurement would be done through django debug toolbar
The way we are going to proceed with this is by seeing the performance of the application and see where all can we optimize it domain by domain. To perform the assessment on the site we would be using a bunch of tools, the most important one being django debug toolbar and chrome’s network tab. We are going to hit the front-end portion first and move forward from there.
Optimizing the Front-end:
Typically when you are looking to optimize the application on the front-end we should look for the entire stack to understand how our app is working. This approach should always be followed in all cases as it gives you a better perspective on how things are functioning.
Charcha uses server-side rendering instead of client-side rendering. This on its own solves a lot of problems for us. How?? When performing client-side rendering, your request loads the page markup, its CSS, and its JavaScript. The problem is that all the code is not loaded at once. Instead what happens is JavaScript loads and then makes another request, gets a response and generates the required HTML whereas, with server-side rendering, your initial request loads the page, layout, CSS, JavaScript, and content. So basically, the server does everything for you.
The moment I got to know that Charcha is rendering its template from the server, my focused turned towards looking at only caching and minification of the pages (to be honest this should be present in all applications).
* Caching Approach:
Before we start writing any code I want you to understand the working of caching in server-side rendering and how powerful it really is? As you may know, whenever there is an endpoint which returns any data, it can generally be cached. So the main question is that can we cache HTML elements? Yes, by rendering on the server we can easily cache our data.
So what’s going to happen is that the first time your client will get a response and that response will now be cached, so the next time when the same response is made not only will your browser have to do the rendering, your server will also not have to. Now that we have an approach for caching we can start implementing it. In order to perform server-side caching, we are going to use whitenoise Now to integrate whitenoise in our Django app, we just have to follow the following steps:
Configuring static files: In Django this isa pretty common approach where you need to add a path of your static files in your settings.py file.
Enable WhiteNoise: We need to add the whitenoise to our middleware in our settings.py. Do not forget about the hierarchy of your MIDDLEWARE_CLASSES, and whitenoise middleware should be above all middleware’s apart from Django’s SecurityMiddleware.
Now whitenoise is going to start serving all your static files but our main purpose for caching is still not done. One thing to note here is that whitenoise also supports compression which we can use.
Whitenoise Compression and Caching support: whitenoise has a storage backend which automatically takes care of the compression of the static files and associates each file with a unique identifier so that these files can be cached forever. To exploit this feature all we have to do is add the following lines in our settings.py
Handling Content Delivery Network: Although we have enabled caching we should still look at CDN to gain maximum efficiency. As whitenoise provides appropriate headers, our CDN can serve the cache files and make sure that for duplicate responses we are not hitting the application again and again, rather serve those request by itself. All we have to do is set an ENV variable as DJANGO_STATIC_HOST and access it in settings.py.
WhiteNoise in development: This is one of the main parts as whenever we run the runserver command, django takes over and handles all the static files on its own. So we will not be using whitenoise as effectively as we want to. For using whitenoise what we need to do is disable Django’s static file handling and allow WhiteNoise to take over the handling of all the static files. So we need to edit our settings.pyand add whitenoise.runserver_nostatic immediately above django.contrib.staticfiles.
INSTALLED_APPS = [
...
# Disable Django's own staticfiles handling in favour of WhiteNoise, for
# greater consistency between gunicorn and `./manage.py runserver`. See:
# http://whitenoise.evans.io/en/stable/django.html#using-whitenoise-in-development
'whitenoise.runserver_nostatic',
'django.contrib.staticfiles',
...
]
Caching images: There are a few available settings which could be used to configure whitenoise. We are going to try to cache the images for a longer duration of time so as to gain some more performance. For this all we have to do is add awhitenoise header function which would basically look for all the images and cache them for us. So we write something like:
def cache_images_forever(headers, path, url):
"""Force images to be cached forever"""
tokens = path.split(".")
if len(tokens) > 1:
extension = tokens[-1].lower()
if extension in ('png', 'jpg', 'jpeg', 'ico', 'gif'):
headers['Cache-Control'] = 'public, max-age=315360000'
WHITENOISE_ADD_HEADERS_FUNCTION = cache_images_forever
Now our caching for the front-end is complete. Let’s move on to the second phase of front-end optimization and try to minify our files.
* Minifying the Files:
For minifying our files we are going to use spaceless template tags. Although this will not minify our files per se, it is still going to give us a better result as it would help us reduce our page weight. How?? Well, spaceless template tagsremoves whitespace between HTML tags. This includes tab characters and newlines. This is really easy to implement in Django templates. All we need to add is spaceless and close it with endspacelessin our base.html. As our base.html is going to be used everywhere as the basic skeleton, we can be sure that it will be applied to all the other templates within it as well.
Now that we are done with our front-end optimization let’s move to our back-end. This is perhaps the one place where we would be able to achieve the maximum amount of efficiency.
Optimizing the Back-end:
Ideally, the flow for optimizing your code is to move from your queries to how your Django is functioning. In queries, we need to see the number of queries, the amount of time it takes to execute the query and how our Django ORM’S are working. Internally Django already does a lot for us but we can optimize its queries even further. We need to start scavenging the code and check the total number of query calls per page. There are a few ways to do this. The most obvious one being logging all the queries in sql.log and start reading the queries from there. There is one other way of accomplishing this, that is by using django debug toolbar.
Now django debug toolbar is a really powerful tool and extremely easy to use. It helps in debugging responses and provides us with a bunch of configurable panels that we could use. We are mainly going to use this to see how quick our queries are and if we are performing any redundant queries.
Django Debug Toolbar
So let’s first integrate the toolbar in Charcha. To install django debug toolbar we are going to follow this doc. Its pretty straightforward and easy to implement. So first we need to install the package using pip.
$ pip install django-debug-toolbar
One thing to note here is that if you are using a virtualenv avoid using sudo. Ideally we should not be using sudo anyways if we are in a virtualenv. Now our django debug toolbar is installed. We need to now add it in our settings.pyINSTALLED_APPS by adding debug_toolbar.
Now we need to put the debug toolbar in our middleware. Since there is no preference of the django debug toolbar middleware the middleware stack we can add it wherever we see fit.
Now we need to add the url to configure the toolbar. We just need to add the url and put it in our DEBUG mode, the rest django debug toolbar will take care of, on its own.
from django.conf import settings
if settings.DEBUG:
import debug_toolbar
urlpatterns = [
url(r'^__debug__/', include(debug_toolbar.urls)),
] + urlpatterns
There are also a few configurations that we could use but for now we are going to set it to default as its not required (with the correct version this should be done automatically).
DEBUG_TOOLBAR_PATCH_SETTINGS = False
Also, since we are using our local we need to set the following INTERNAL_IP for django debug toolbar to understand.
INTERNAL_IPS = ('127.0.0.1',)
And now we test. We can now start checking the number of queries that are being run and how much time they are taking to execute as well.
This part is actually a bit easy as all we have to do is set a benchmark on the basis of the amount of data that we have. We also need to consider the higher effect where if we have a lot of data within a lot of foreign keys, we might need to start using indexes there.
To show how we are going to refactor the code we went ahead and started seeing the performance of all the pages. Most refactoring would mostly look at how we could reduce the number of queries.
Now according to the django debug toolbar there are a lot of queries that we are making 8 queries whenever we are making our call to see the post. This would, later on, start giving us problems if we don’t eliminate a few of them. The way we are going to approach optimizing queries is in subparts as follows:
Solving N+1 queries:
We can solve the problem of N+1 queries simply by using prefetch_related and select_related in Charcha. With the two functions, we can have a tremendous performance boost as well. But first, we need to understand what exactly is it that they do and how can we implement it in Charhca.
* select_related:
select_related should be used when the object that you are selecting in a single object of a model, so something like a ForeignKey or a OneToOneField. So whenever you make such a call, select_related would do a join of the two tables and send back the result to you thereby reducing an extra query call to the ForeignKey table. Let’s see an example to better understand how we can integrate this in Charcha. We are going to take the example of the Post model which looks something like this:
class Post(Votable):
...
objects = PostsManager()
title = models.CharField(max_length=120)
url = models.URLField(blank=True)
text = models.TextField(blank=True, max_length=8192)
submission_time = models.DateTimeField(auto_now_add=True)
num_comments = models.IntegerField(default=0)
...
Do note that we have a custom manager defined, so whichever query we need to execute we can define it in our manager. Now in your first glance, you can see that our class Post is inheriting from Votable, so we now need to see what is happening in this class.
Whenever we make a call to check the Author of our Post we will be doing an extra call to the database. So now we go to our custom manager and change the way are fetching the data.
class PostsManager(models.Manager):
def get_post_with_my_votes(self, post_id, user):
post = Post.objects\
.annotate(score=F('upvotes') - F('downvotes'))\
.get(pk=post_id)
...
return post
If we use the django debug toolbar you would see that whenever we do a call like get_post_with_my_votes().author, we are going to be executing an extra query to the User table.
This is not required and can be rectified easily by using select_related. What do we have to do? Just add select_related to the query.
class PostsManager(models.Manager):
def get_post_with_my_votes(self, post_id, user):
post = Post.objects\
.annotate(score=F('upvotes') - F('downvotes'))\
.select_related('author').get(pk=post_id)
...
return post
And that’s it. Our redundant query should be removed. Lets check it using django debug toolbar.
* prefetch_related:
We can use prefetch_related when we are going to get a set of things, so basically something like a ManyToManyField or a reverse ForeignKey. How does this help? Well, the way prefetch_related works is it makes another query and therefore reduces the redundant columns in the original object. This as of now is not really required so we are going to let it be.
* Query in a loop:
Though this is not done anywhere in Charcha but this a practise which a lot of people follow without realising its impact. Although this seems pretty basic I still feel that requires its separate section.
post_ids = Post.objects.filter(id = ?).values_list('id', flat=True)
authors = []
for post in post_ids:
#Disaster as when we would have a lot of post_ids say around 10,000
#we would be making that many calls, basically (n+1) calls.
post = Author.objects.filter(id= post_ids)
authors.append(post)
The above example is just a sample of how disasterous a query in a loop could be for a large dataset and this above example can easily be solved by the previous discussion (on select_related and prefetch_related) which we had.
Denormalization:
I recommend using denormalization only if we have some performance issues and not prematurely start optimizing it. We should check the queries before we start with our denormalization as it does not make any sense if we keep on adding more complexity if it is not impacting our performance.
The best place to explain denormalization implementation in Charcha is in the Votable model as done in the 2nd blog of this series. Why the Votable table? This is because we want to show the score i.e. upvotes – downvotes and the comments on the home page. We could make a join on the Votable table and call it from there but it would slow down our system. Instead what we are doing is, adding the fields of upvotes, downvotes and flag in the Votable model. This would in turn reduce our calls.
Now we can just inherit these properties in whichever models we require and from there we can move forward. Although this seems pretty easy to implement it does have a drawback. Every time there is some changes that is made, we would have to update these fields. So instead of making a JOIN we would rather have a more complex UPDATE.
WBS for Tracking Comments Hierarchy
This is also a form of denormalization. Each comment needs a reference to its parent comment and so on , so it basically makes something like the tree structure.
class Comment(Votable):
...
wbs = models.CharField(max_length=30)
...
The problem here is that self-referential calls are exceedingly slow. So we can refactor this approach and add a new field called wbs which would help us track the comments as a tree. How would it work? Every comment would have a code, which is a dotted path. So the first comment would have the code “.0001” and the second top-level comment would have the code “.0002” and so on. Now if someone responds to the first comment it gets a code of “.0001.0001”. This would help us avoid doing self-referential queries and use wbs instead.
Now the limitation for this field is we would only allow 9999 comments at each level and the height of the wbs tree would only go till 6, which is sort of acceptable in our case. But in the case of having to go through a large database, we would have to index this field as well. We would discuss this in the next section.
Adding Indexes
Indexes is one of the many standard DB optimization techniques and django provides us with a lot of tools to add these indexes. Once we have identified which all queries are taking a long time we can use Field.db_index or Meta.index_together to add these from Django.
Before we start adding indexes we need to identify where all should we add these properly and to do that we will use django debug toolbar to see how fast we get our response. Now we are going to look at the post which we had before and we are going to track its queries. We are going to select a query which we could easily optimize indexes
SELECT ••• FROM "votes" WHERE ("votes"."type_of_vote" IN ('1', '2') AND "votes"."voter_id" = '2' AND "votes"."content_type_id" = '7' AND "votes"."object_id" = '1')
Now, this particular query is taking 1.45s to execute. Now, all we have to see is the table and which field we could add the index on. Since this query belongs to model Votes we are going to add the index on content_type_id and object_id. How?
class Vote(models.Model):
class Meta:
db_table = "votes"
index_together = [
["content_type", "object_id"],
]
And that’s all we have to do. Now we run our migrations and check our performance.
Now, this query is taking only 0.4 seconds to execute and that is how easy it is to implement indexes.
Django QuerySets are LAZY
One thing to note when using django is that django querysets are lazy , what that means is queryset does not do any database activity and django will only run the query when the queryset is evaluated. So if we make a call from the Post model like
This would make three separate queries which is not really required.
Caching sessions
One thing to notice using the django debug toolbar is that almost all the pages have a query made to retrieve the Django session.
The query that we are tackling is given below and since its being used in almost all the places we can simply cache it once and reap the benefits everywhere else.
SELECT ••• FROM "django_session" WHERE ("django_session"."session_key" = '''6z1ywga1kveh58ys87lfbjcp06220z47''' AND "django_session"."expire_date" > '''2017-05-03 10:56:18.957983''')
By default, Django stores the sessions in our database and expects us to occasionally prune out old entries which we would not be doing.
So on each request, we are doing a SQL query to get the session data and another to grab the User object information. This is really not required and we can easily add a cache here to reduce the load on our server. But the question still remains on which store should we use? From a higher operational point of view, introducing a distributed data store like redis is not really required. Instead, we could simply use cookie-based sessions here.
Do note that we would not be using cookie-based sessions for highly secure sites but Charcha does not need to be highly secure.
How do we implement it?
Using cookie-based sessions is very easy to do. We can simply follow the steps given in this link. All we have to do is add the following in our settings.py (or common.py as per Charcha) and see the magic happen. We will switch to storing our sessions in our cache and easily remove a SQL query from every single request to our site.
In this post, we have discussed how one should proceed when optimizing their site. We have tackled all the domains, discussed the various techniques to optimize a Django site and talked about the tools like which django debug toolbar can be used for a sites assessment.